by soundwavescience
New musical instruments
A presentation for Berklee BTOT 2015 http://www.berklee.edu/faculty

Around the year 1700, several startup ventures developed prototypes of machines with thousands of moving parts. After 30 years of engineering, competition, and refinement, the result was a device remarkably similar to the modern piano.
What are the musical instruments of the future being designed right now?
- new composition tools,
- reactive music,
- connecting things,
- sensors,
- voices,
- brains
Notes:
predictions?
Ray Kurzweil’s future predictions on a timeline: http://imgur.com/quKXllo (The Singularity will happen in 2045)
In 1965 researcher Herbert Simon said: “Machines will be capable, within twenty years, of doing any work a man can do”. Marvin Minsky added his own prediction: “Within a generation … the problem of creating ‘artificial intelligence’ will substantially be solved.” https://forums.opensuse.org/showthread.php/390217-Will-computers-or-machines-ever-become-self-aware-or-evolve/page2
Patterns
Are there patterns in the ways that artists adapt technology?
For example, the Hammond organ borrowed ideas developed for radios. Recorded music is produced with computers that were originally as business machines.
Instead of looking forward to predict future music, lets look backwards to ask,”What technology needs to happen to make musical instruments possible?” The piano relies upon a single-escapement (1710) and later a double-escapement (1821). Real time pitch shifting depends on Fourier transforms (1822) and fast computers (~1980).
Artists often find new (unintended) uses for tools. Like the printing press.
New pianos
The piano is still in development. In December 2014, Eren Başbuğ composed and performed music on the Roli Seaboard – a piano keyboard made of 3 dimensional sensing foam:
Here is Keith McMillen’s QuNexus keyboard (with Polyphonic aftertouch):
https://www.youtube.com/watch?v=bry_62fVB1E
Experiments
Here are tools that might lead to new ways of making music. They won’t replace old ways. Singing has outlasted every other kind of music.
These ideas represent a combination of engineering and art. Engineers need artists. Artists need engineers. Interesting things happen at the confluence of streams.
Analysis, re-synthesis, transformation
Computers can analyze the audio spectrum in real time. Sounds can be transformed and re-synthesized with near zero latency.
Infinite Jukebox
Finding alternate routes through a song.
by Paul Lamere at the Echonest
Echonest has compiled data on over 14 million songs. This is an example of machine learning and pattern matching applied to music.
http://labs.echonest.com/Uploader/index.html
Try examples: “Karma Police”, Or search for: “Albert Ayler”)
- Analyze your own music: https://reactivemusic.net/?p=18026
Remixing a remix
“Mindblowing Six Song Country Mashup”: https://www.youtube.com/watch?v=FY8SwIvxj8o (start at 0:40)
Local file: Max teaching examples/new-country-mashup.mp3
More about Echonest
- Music Machinery by Paul Lamere: http://musicmachinery.com
- Echonest segment analysis player: https://reactivemusic.net/?p=6296
Feature detection
Looking at music under a microscope.
removing music from speech
First you have to separate them.
SMS-tools
by Xavier Serra and UPF
Harmonic Model Plus Residual (HPR) – Build a spectrogram using STFT, then identify where there is strong correlation to a tonal harmonic structure (music). This is the harmonic model of the sound. Subtract it from the original spectrogram to get the residual (noise).
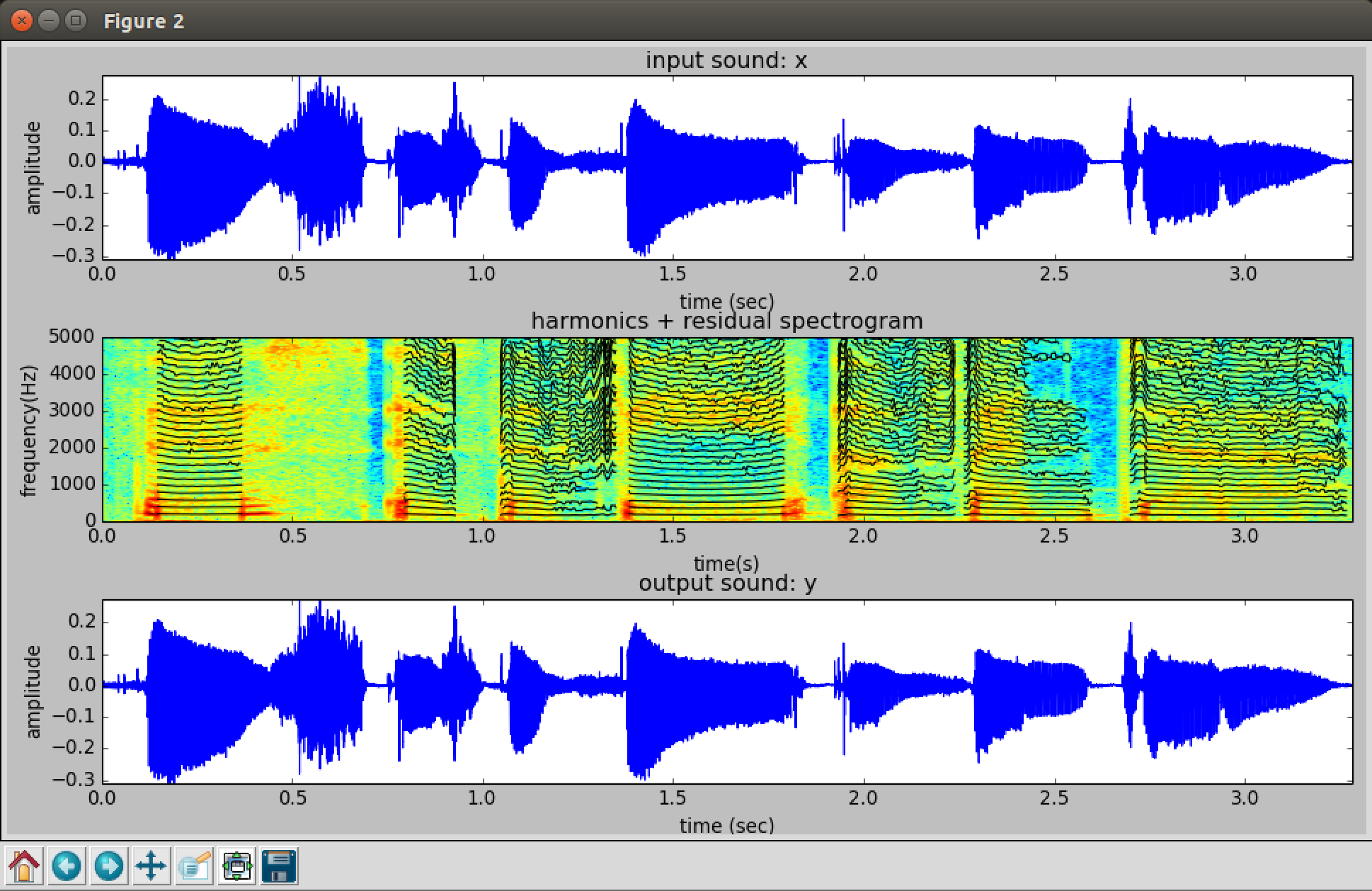
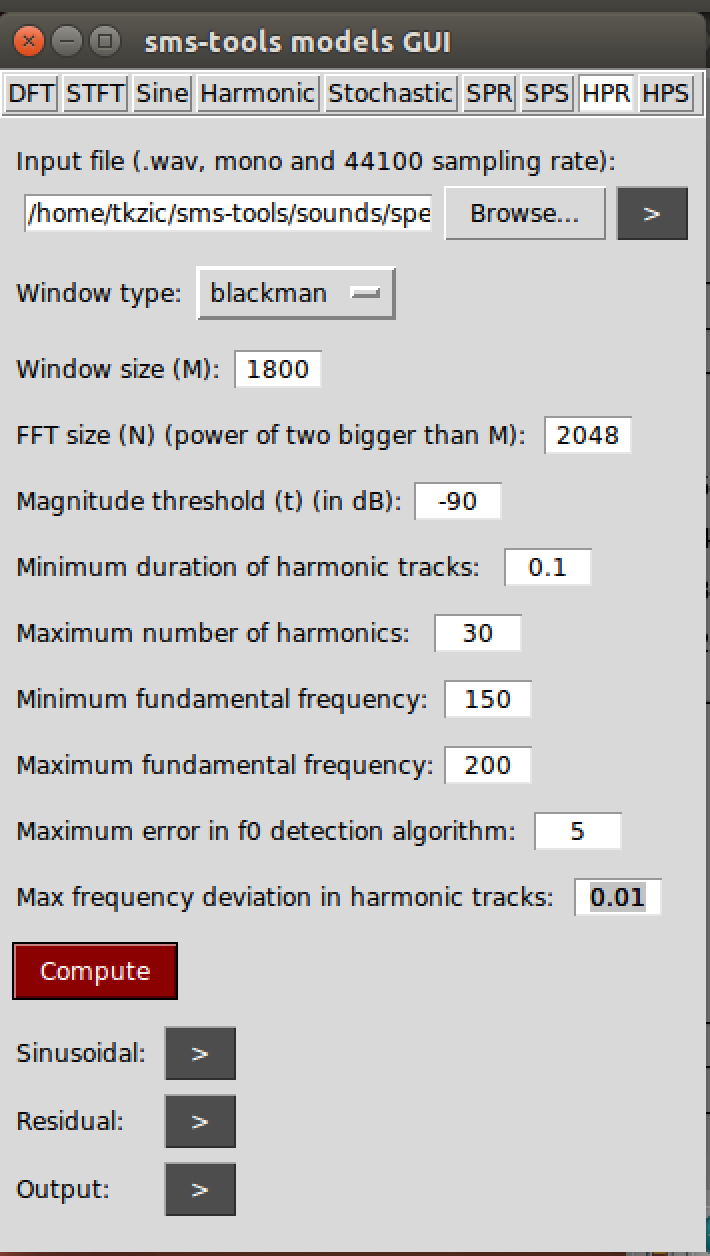
Settings for above example:
- Window size: 1800 (SR / f0 * lobeWidth) 44100 / 200 * 8 = 1764
- FFT size: 2048
- Mag threshold: -90
- Max harmonics: 30
- f0 min: 150
- f0 max: 200
Many kinds of features
- Low level features: harmonicity, amplitude, fundamental frequency
- high level features: mood, genre, danceability
Examples of feature detection
- Acoustic Brainz: https://reactivemusic.net/?p=17641 (typical analysis page)
- Freesound (vast library of sounds): https://www.freesound.org – look at “similar sounds”
- Essentia (open source feature detection tools) https://github.com/MTG/essentia
- “What We Watch” – Ethan Zuckerman https://reactivemusic.net/?p=10987
Music information retrieval
Finding the drop
“Detetcting Drops in EDM” – by Karthik Yadati, Martha Larson, Cynthia C. S. Liem, Alan Hanjalic at Delft University of Technology (2014) https://reactivemusic.net/?p=17711
Polyphonic audio editing
Blurring the distinction between recorded and written music.
Melodyne
by Celemony
http://www.celemony.com/en/start
A minor version of “Bohemian Rhapsody”: http://www.youtube.com/watch?v=voca1OyQdKk
Music recognition
“How Shazam Works” by Farhoud Manjoo at Slate: https://reactivemusic.net/?p=12712, “About 3 datapoints per second, per song.”
- Music fingerprinting: https://musicbrainz.org/doc/Fingerprinting
- Humans being computers. Mystery sounds. (Local file: Desktop/mystery sounds)
- Is it more difficult to build a robot that plays or one that listens?
Sonographic sound processing
Transforming music through pictures.
by Tadej Droljc
https://reactivemusic.net/?p=16887
(Example of 3d speech processing at 4:12)
local file: SSP-dissertation/4 – Max/MSP/Jitter Patch of PV With Spectrogram as a Spectral Data Storage and User Interface/basic_patch.maxpat
Try recording a short passage, then set bound mode to 4, and click autorotate
Spectral scanning in Ableton Live:
http://youtu.be/r-ZpwGgkGFI
Web Audio
Web browser is the new black
Noteflight
by Joe Berkowitz
http://www.noteflight.com/login

Plink
by Dinahmoe
http://labs.dinahmoe.com/plink/
Can you jam over the internet?
What is the speed of electricity? 70-80 ms is the best round trip latency (via fiber) from the U.S. east to west coast. If you were jamming over the internet with someone on the opposite coast it might be like being 100 ft away from them in a field. (sound travels 1100 feet/second in air).
Global communal experiences – Bill McKibben – 1990 “The Age of Missing Information”
More about Web Audio
- A quick Web Audio introduction: https://reactivemusic.net/?p=17600
- Gibber by Charlie Roberts http://gibber.mat.ucsb.edu/
Conversation with robots
Computers finding meaning
The Google speech API
https://reactivemusic.net/?p=9834

The Google speech API uses neural networks, statistics, and large quantities of data.
Microsoft: real-time translation
- German/English http://digg.com/video/heres-microsoft-demoing-their-breakthrough-in-real-time-translated-conversation
- Skype translator – Spanish/English: http://www.skype.com/en/translator-preview/
Reverse entropy
InstantDecomposer
Making music from from sounds that are not music.
by Katja Vetter
. (InstantDecomposer is an update of SliceJockey2): http://www.katjaas.nl/slicejockey/slicejockey.html
- local: InstantDecomposer version: tkzic/pdweekend2014/IDecTouch/IDecTouch.pd
- local: slicejockey2test2/slicejockey2test2.pd
More about reactive music
- RJDJ apps – create personal soundtracks from the environment
- “Lyrebirds” by Christopher Lopez https://www.youtube.com/watch?v=Ouws45R2iXg
Sensors and sonification
Transforming motion into music
Three approaches
- earcons (email notification sound)
- models (video game sounds)
- parameter mapping (Geiger counter)
Leap Motion
camera based hand sensor
“Muse” (Boulanger Labs) with Paul Bachelor, Christopher Konopka, Tom Shani, and Chelsea Southard: https://reactivemusic.net/?p=16187
Max/MSP piano example: Leapfinger: https://reactivemusic.net/?p=11727

local file: max-projects/leap-motion/leapfinger2.maxpat
Internet sensors project
Detecting motion from the Internet
https://reactivemusic.net/?p=5859
Twitter streaming example
https://reactivemusic.net/?p=5786

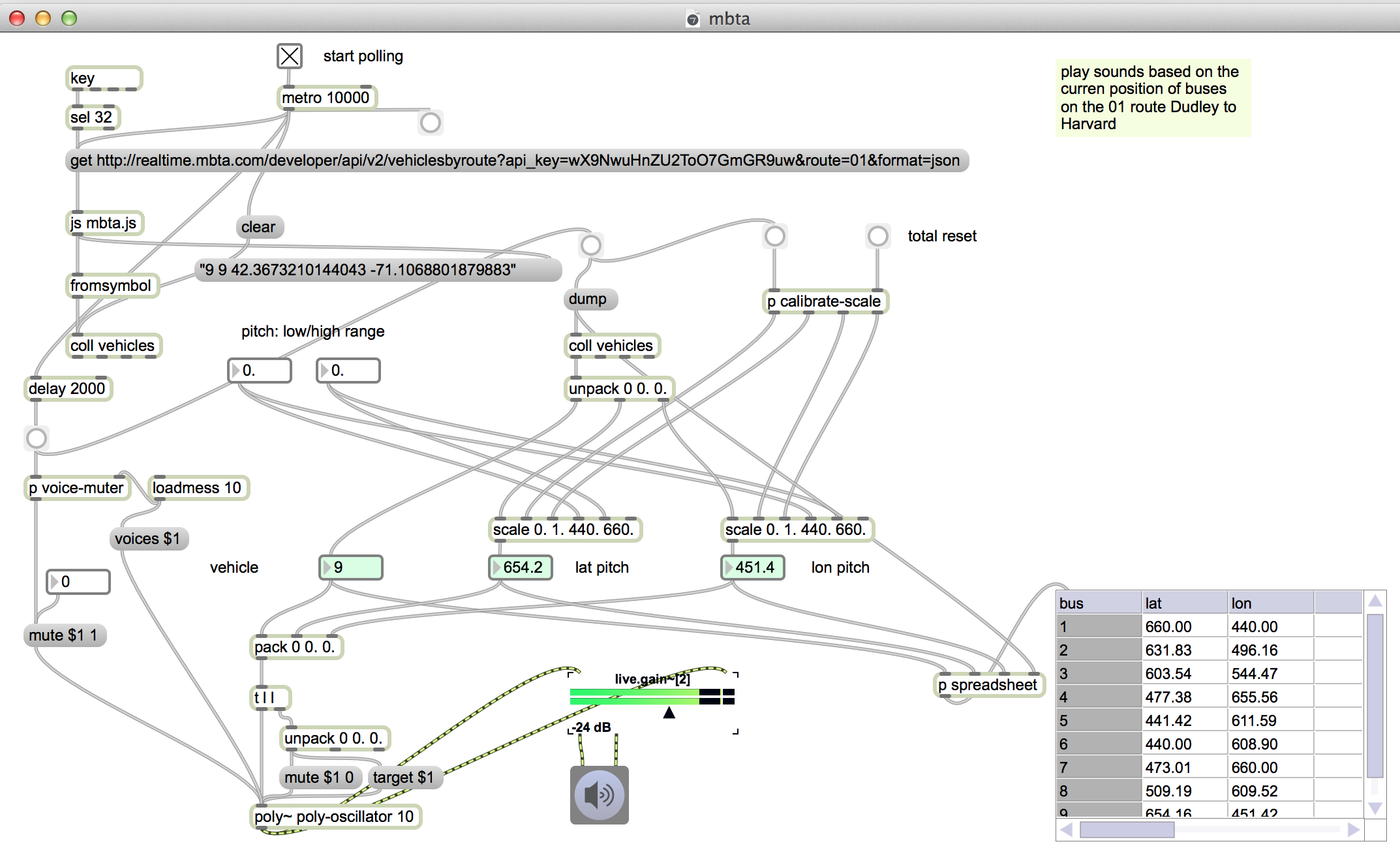
MBTA bus data
Sonification of Mass Ave buses, from Harvard to Dudley
https://reactivemusic.net/?p=17524
Stock market music
https://reactivemusic.net/?p=12029
More sonification projects
Vine API mashup
By Steve Hensley
Using Max/MSP/jitter
local file: tkzic/stevehensely/shensley_maxvine.maxpat
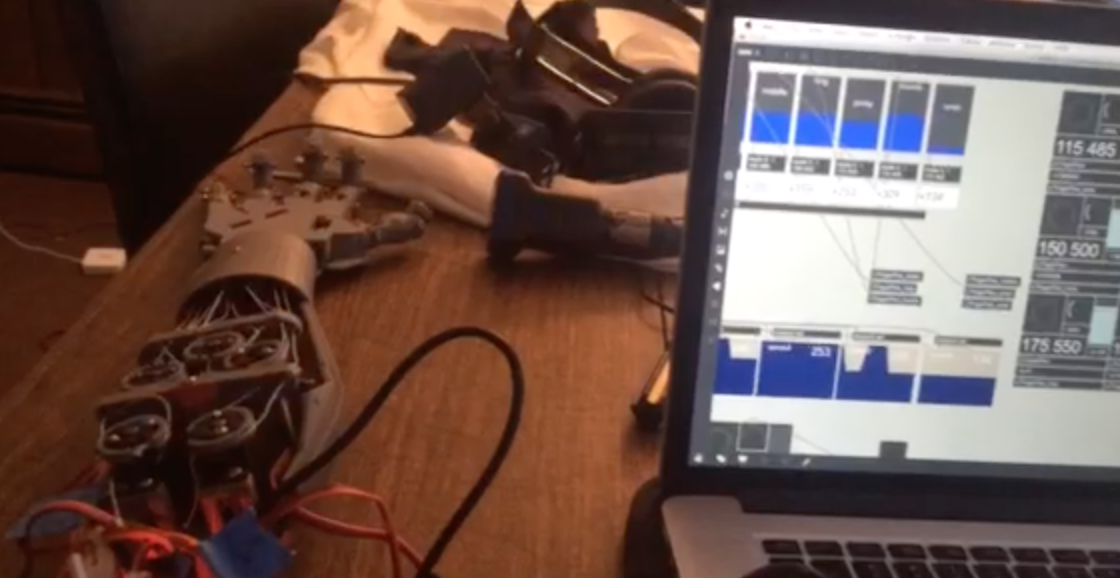
Audio sensing gloves for spacesuits
By Christopher Konopka at future, music, technology
http://futuremusictechnology.com
Computer Vision
Sensing motion with video using frame subtraction
by Adam Rokhsar

https://reactivemusic.net/?p=7005
local file: max-projects/frame-subtraction
The brain
Music is stored all across the brain.
Mouse brain wiring diagram
The Allen institute
https://reactivemusic.net/?p=17758
“Hacking the soul” by Christof Koch at the Allen institute
(An Explanation of the wiring diagram of the mouse brain – at 13:33) http://www.technologyreview.com/emtech/14/video/watch/christof-koch-hacking-the-soul/
OpenWorm project
A complete simulation of the nematode worm, in software, with a Lego body (320 neurons)
: https://reactivemusic.net/?p=17744
AARON
Harold Cohen’s algorithmic painting machine
https://reactivemusic.net/?p=17778
Brain plasticity
A perfect pitch pill? http://www.theverge.com/2014/1/6/5279182/valproate-may-give-humans-perfect-pitch-by-resetting-critical-periods-in-brain
DNA
Could we grow music producing organisms? https://reactivemusic.net/?p=18018
Two possibilities
Rejecting technology?

An optimistic future?
There is a quickening of discovery: internet collaboration, open source, linux, github, r-pi, Pd, SDR.
“Robots and AI will help us create more jobs for humans — if we want them. And one of those jobs for us will be to keep inventing new jobs for the AIs and robots to take from us. We think of a new job we want, we do it for a while, then we teach robots how to do it. Then we make up something else.”
“…We invented machines to take x-rays, then we invented x-ray diagnostic technicians which farmers 200 years ago would have not believed could be a job, and now we are giving those jobs to robot AIs.”
Kevin Kelly – January 7, 2015, reddit AMA http://www.reddit.com/r/Futurology/comments/2rohmk/i_am_kevin_kelly_radical_technooptimist_digital/
Will people be marrying robots in 2050? http://www.livescience.com/1951-forecast-sex-marriage-robots-2050.html
“What can you predict about the future of music” by Michael Gonchar at The New York Times https://reactivemusic.net/?p=17023
Jim Morrison predicts the future of music:
More areas to explore
- NIME (New interfaces for musical expression) http://en.wikipedia.org/wiki/New_Interfaces_for_Musical_Expression
- Immersive virtual musical instruments http://en.wikipedia.org/wiki/Immersive_virtual_musical_instrument
- I’m thinking of something: http://imthinkingofsomething.com
Processing shortwave radio sounds
Using the python sms-tools library.
sms-tools: https://github.com/MTG/sms-tools
Here is a song made from the processed sounds:
mp3 version:
This project was an assignment for the Coursera “Audio Signal Processing for Music Applications” course. https://www.coursera.org/course/audio
Source material
Sounds were recorded from a shortwave radio between 5-10MHz.
freesound.org links to the sounds:
- am_interference_7mhz: https://www.freesound.org/people/tkzic/sounds/258095/
- buzz_pulse_7mhz: https://www.freesound.org/people/tkzic/sounds/258096/
- digital_pulse_7mhz: https://www.freesound.org/people/tkzic/sounds/258098/
- cw_7mhz1_small: https://www.freesound.org/people/tkzic/sounds/258097/
- wwv_5mhz_short: https://www.freesound.org/people/tkzic/sounds/258099/
Processing
am_interference_7mhz.wav
The sound is an AM shortwave broadcast station from between 7-8 MHz. It is speech with atmospheric noise and a digitally modulated carrier at 440Hz in the background.
I tried various approaches to removing the speech and isolating the carrier. But ended up using the following parameters to remove noise and speech, but for most part leaving a 440hz digital mode signal with large gaps in it.
- M=701
- N=1024
- minf0=400
- maxf0=500
- thresh=-90
- max harmonics=50
After more experimentation, the following changes resulted in a cool continuous tone with speechlike quality (but not intelligible) and the background noise is gone.
Here is the full list of parameters:
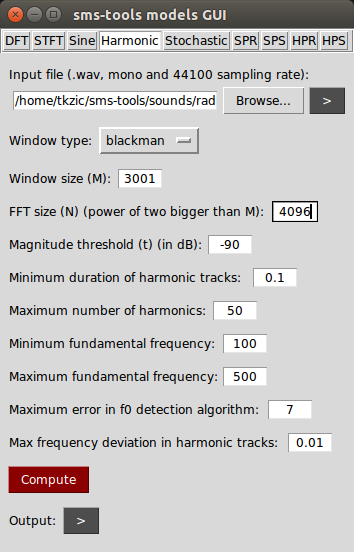
Here is a plot:
Here is the resulting sound of the sinusoidal part of the harmonic model:
buzz_pulse_7mhz.wav
The sound is continuous digital modulation (buzzing) from a shortwave radio between 7-8 MHz. The buzz is around 100Hz with atmospheric background noise.
Transformation using HPS (harmonic plus stochastic) model.
Not very impressive analysis, but the resynthesis had a very cool looking spectrogram due to some frequency shifting.
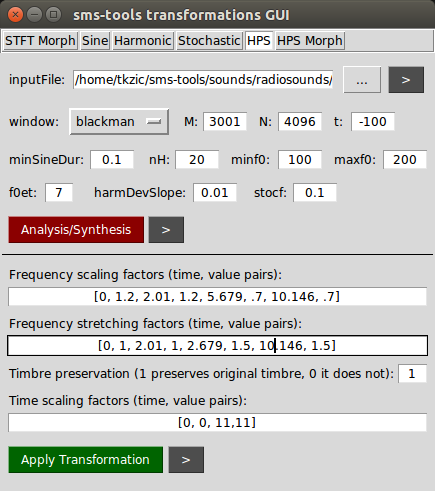
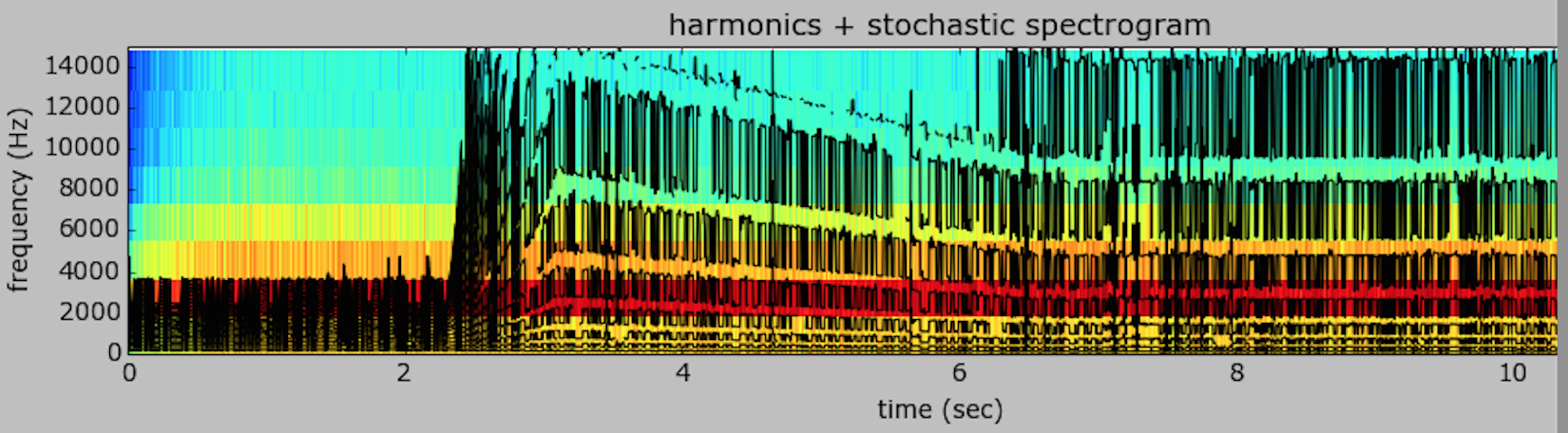
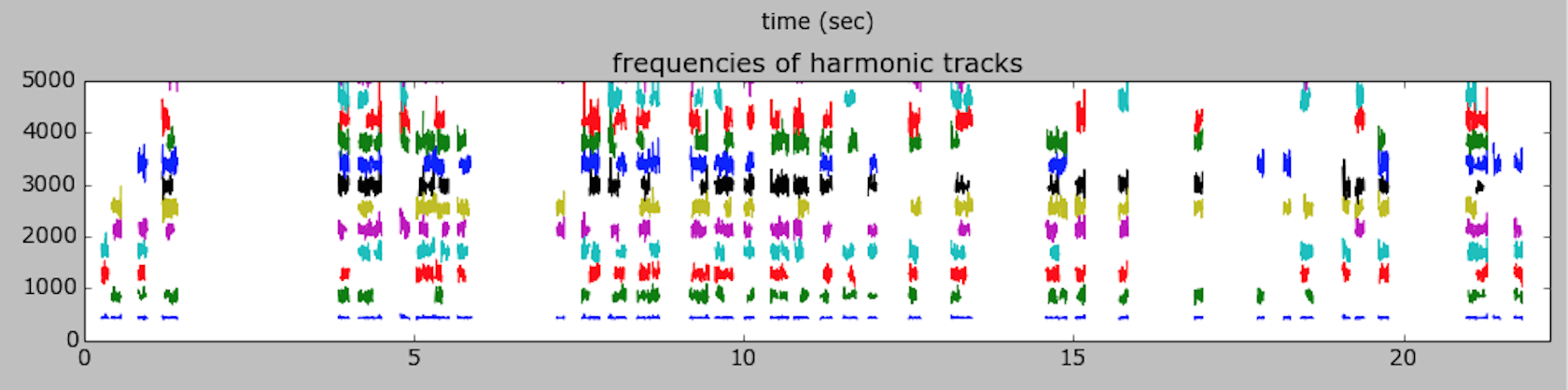
I realized that I had set f0min too high. Went back to using the HPR model without transformation to see if I could separate the tone. Here is the plot:
Here are the resulting sounds transformation (unused) and the sinusoidal/residual results that were used in the track.
source: digital_pulse_7hz.wav
A repeating pulse around from a shortwave radio between 7-8 MHz. The frequency of the pulse is around 1000Hz with a noise component.
Another noise filter – this was way more difficult due to high freq material.
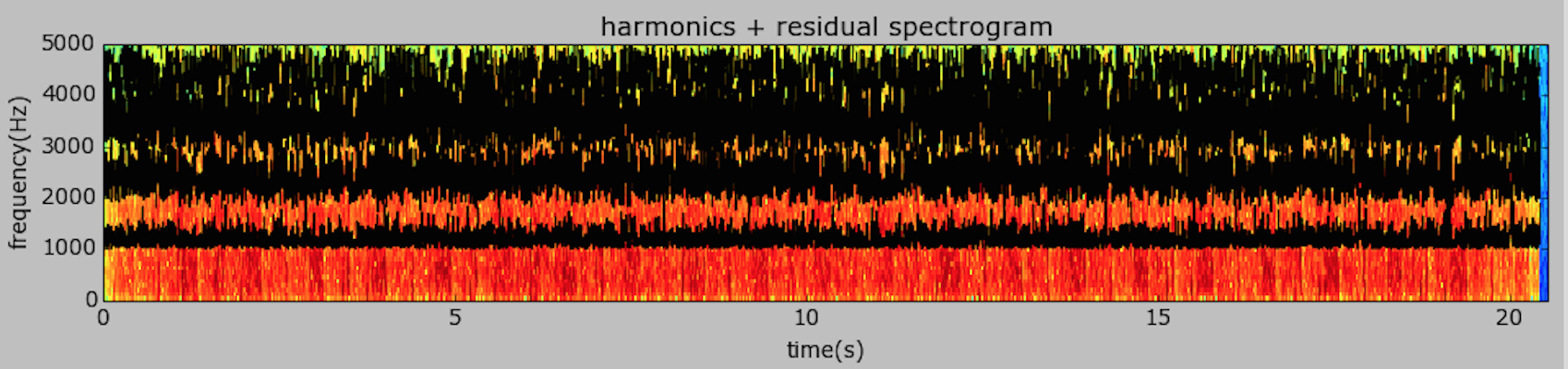
Instead, I went with a downward pitch transform, using the HPS model transform. Here are the resulting sounds from the HPR filter (unused) and the HPS transform.
cw_7mhz1_small.wav
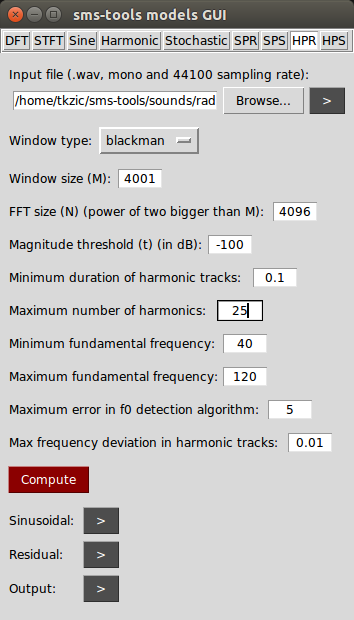
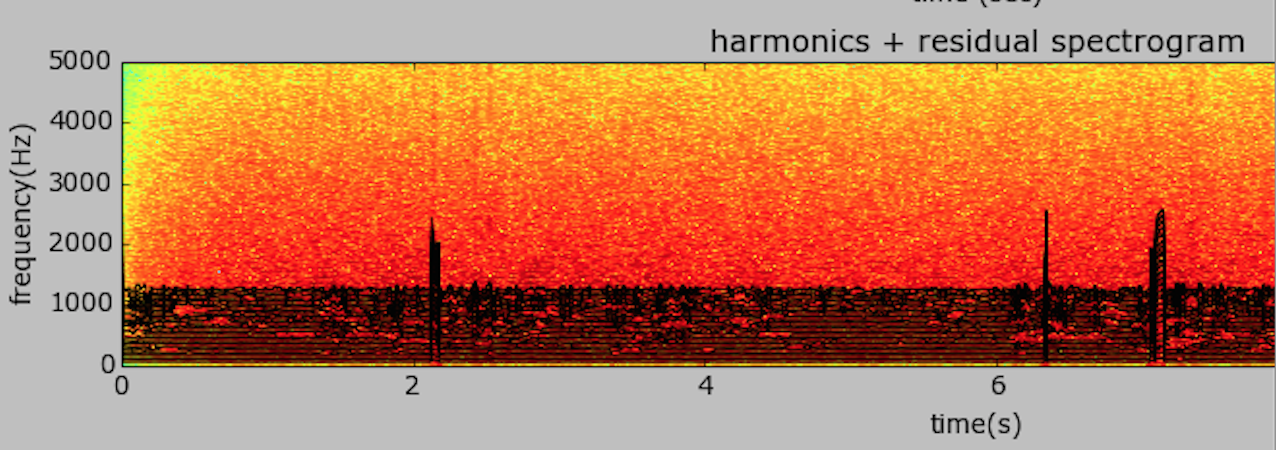
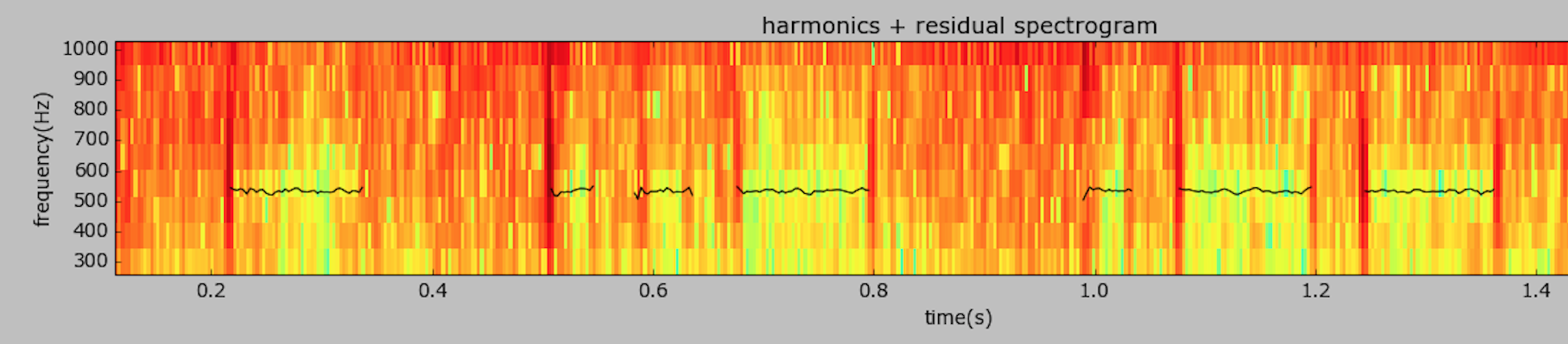
The sound contains typical amateur radio CW signals from the 40 Meter band, with several interfering signals (QRM) and atmospheric noise (QRN). Using the HPR model, I was able to completely isolate and re-synthesize the CW signal, removing all the noise and interfering signals.
Note that you can actually see the morse code letters “T, U, and W” on the spectrogram of model!
Here is the re-synthesized CW sound:
wwv_5mhz_short.wav
The WWV National Bureau of Standards “clock” station at 5MHz. A combination of pulses, tones, speech, and background noise.
I was trying to separate the voice from the rest of the tones and noise. After several hours and various approaches, I gave up. The signal may be too complex to separate using these models. There were some interesting plots with the HPR model
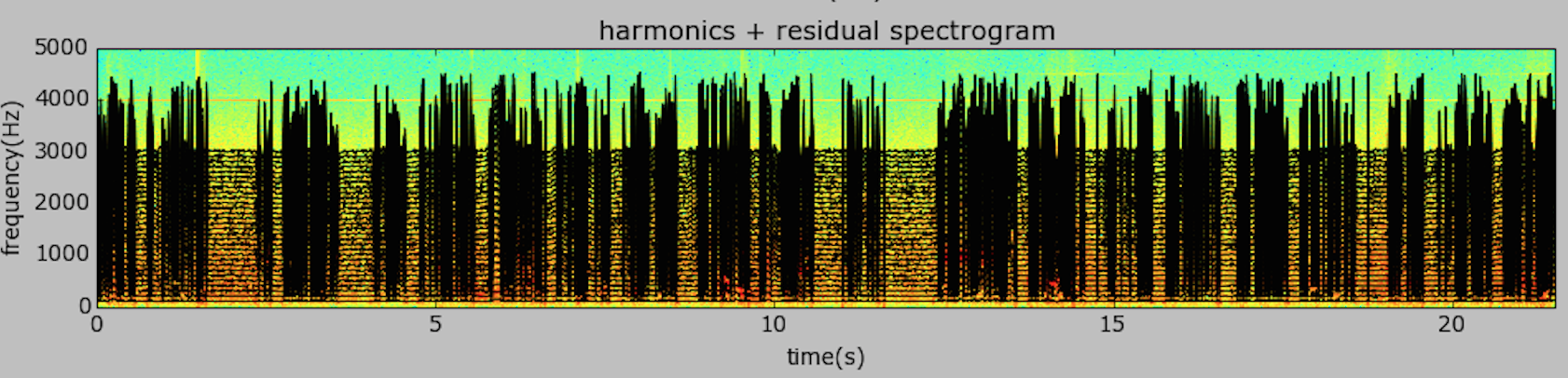
Finally decided to just isolate the 440 Hz. clock pulse from the rest of the signal:

Here is the resulting sound (note that the tone starts several seconds into the sample)
ep-413 DSP week 15
Review
- Syllabus: https://reactivemusic.net/?p=17122
- Ways to approach a project https://reactivemusic.net/?p=17132
- Make machines that make art
- Reverse engineering
- Use the wrong tools
- Abstraction and destruction
- Backwards, extreme, opposite – connect two things
- Ask questions
- Composition tools and dramatic shape https://reactivemusic.net/?p=17157
- Problem solving (pitch detection) and prototyping (Muse) https://reactivemusic.net/?p=17159
- Sound byte composition https://reactivemusic.net/?p=17190
- Convolution and voices https://reactivemusic.net/?p=17211
- (No class this week)
- Granular synthesis, the frequency domain, and phasors https://reactivemusic.net/?p=17360
- Data, Internet API’s, Vine API in Max https://reactivemusic.net/?p=17466
- Communication, Osc, Sonification, MBTA API in Max https://reactivemusic.net/?p=17518
- Filters: analog, digital, other, reversability https://reactivemusic.net/?p=17542
- Web Audio API https://reactivemusic.net/?p=17600
- Feature detection, and Music Information Retrieval https://reactivemusic.net/?p=17689
- Waves: light, radio, water https://reactivemusic.net/?p=17787
- This
Ideas
John Coltrane: You can learn something from everybody, no matter how good or bad they play, everybody has something to say.
Sal Khan: In the future people will take agency for their own education.
For artists, everything is a tool.
Musical squares

DSP animated GIF’s
By Stephane Boucher at dsprelated.com
http://www.dsprelated.com/showarticle/584.php
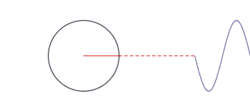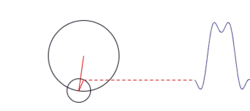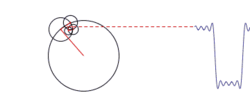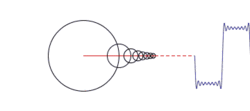
Constructing a square wave with an infinite series
Harmonic Analyzer
Analog spectrum analyzer by Albert Michelson circa. 1897

Documentary by Bill Hammack
Paper by Bill Hammack, Steve Kranz, and Bruce Carpenter
http://www.engineerguy.com/fourier/pdfs/albert-michelsons-harmonic-analyzer.pdf
ep-413 DSP – week 13
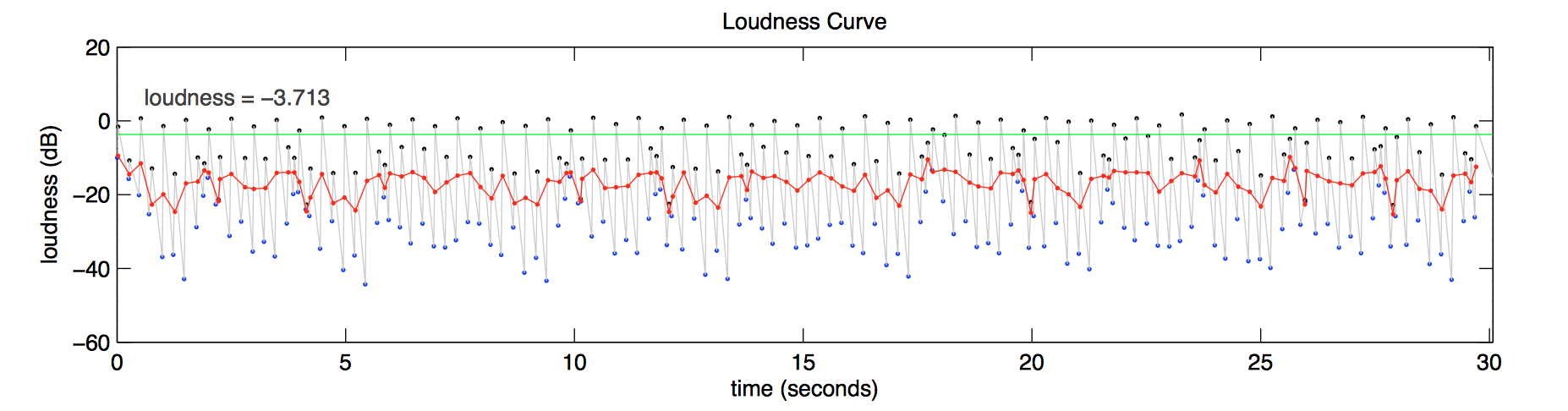
Feature detection and randomness
What could it possibly have to do with my life?
Feature detection
descriptors
- Spectral
- BarkBands, MelBands, ERBBands, MFCC, GFCC, LPC, HFC, Spectral Contrast, Inharmonicity, and Dissonance, …
- Time-domain
- EffectiveDuration, ECR, Loundness, …
- Tonal
- PitchSalienceFunction, PitchYinFFT, HPCP, TuningFrequency, Key, ChordsDetection, …
- Rhythm
- BestTrackerDegara, BeatTrackerMultiFeature, BPMHistogramDescriptors, NoveltyCurve, OnsetDescription, OnsetDetection, Onsets, …
- SFX
- LogAttackTime, MaxToTotal, MinToTotal, TCToTotal, …
- High-level
- Danceability, DynamicComplexity, FadeDetection, SBic, …
-from X. Serra (2014) “Audio Signal Processing for Music Applications”
- low level vs. high level
- single events vs. groups of events
- combinations of descriptors
- order of events (markov chains)
Humans are very good at pattern recognition. Is it a survival mechanism? People who listen to music are very good at analysis. Compared to the abilities of an average child, computer music information retrieval has not yet reached the computational ability of a worm: https://reactivemusic.net/?p=17744
Pattern recognition
(in computer science)
- search engines
- (search by image) https://reactivemusic.net/?p=9847
- translators
- warning systems
- dolphin whistle https://reactivemusic.net/?p=10337
- machine learning – facial recognition: https://reactivemusic.net/?p=17717
Music information retrieval
High-level
- chills: https://reactivemusic.net/?p=17714
- the drop https://reactivemusic.net/?p=17711
- mood: https://reactivemusic.net/?p=17722
- Bobby McFerrin https://reactivemusic.net/?p=555
Low-level
(These demonstrations will be done in Ubuntu Linux 14.04.1)
- SMS tools https://reactivemusic.net/?p=17626
- Essentia https://reactivemusic.net/?p=17656
1. Separating and removing musical tones from speech
1a. Harmonic plus residual model (HPR) in sms-tools (speech-female 150-200 Hz. , and sax phrase)
1b. Do the same thing with transformation model
What about pitch salience and chroma?
2. descriptors
(use workspace/A9)
import soundAnalysis as SA
Here is the list of descriptors that are donwloaded:
Index — Descriptor
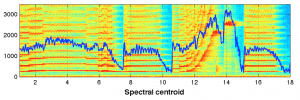
0 — lowlevel.spectral_centroid.mean
1 — lowlevel.dissonance.mean
2 — lowlevel.hfc.mean
3 — sfx.logattacktime.mean
4 — sfx.inharmonicity.mean
5 — lowlevel.spectral_contrast.mean.0
6 — lowlevel.spectral_contrast.mean.1
7 — lowlevel.spectral_contrast.mean.2
8 — lowlevel.spectral_contrast.mean.3
9 — lowlevel.spectral_contrast.mean.4
10 — lowlevel.spectral_contrast.mean.5
11 — lowlevel.mfcc.mean.0
12 — lowlevel.mfcc.mean.1
13 — lowlevel.mfcc.mean.2
14 — lowlevel.mfcc.mean.3
15 — lowlevel.mfcc.mean.4
16 — lowlevel.mfcc.mean.5
2a. euclidian distance
What happens when you look at multiple descriptors
In [22]: SA.descriptorPairScatterPlot( ‘tmp’, descInput=(0,5))
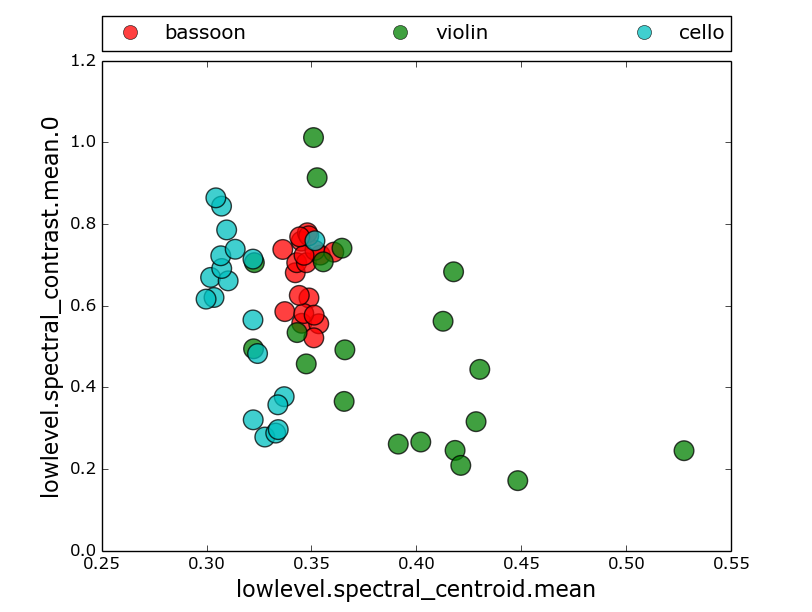
2b. k- means clustering
What descriptors best classify sounds into instrument groups?
SA.clusterSounds(‘tmp’, nCluster = 3, descInput=[0,2,9])
In [21]: SA.clusterSounds(‘tmp’, nCluster = 3, descInput=[0,2,9])
(Cluster: 0) Using majority voting as a criterion this cluster belongs to class: violin
Number of sounds in this cluster are: 15
sound-id, sound-class, classification decision
[[‘61926’ ‘violin’ ‘1’]
[‘61925’ ‘violin’ ‘1’]
[‘153607’ ‘violin’ ‘1’]
[‘153629’ ‘violin’ ‘1’]
[‘153609’ ‘violin’ ‘1’]
[‘153608’ ‘violin’ ‘1’]
[‘153628’ ‘violin’ ‘1’]
[‘153603’ ‘violin’ ‘1’]
[‘153602’ ‘violin’ ‘1’]
[‘153601’ ‘violin’ ‘1’]
[‘153600’ ‘violin’ ‘1’]
[‘153610’ ‘violin’ ‘1’]
[‘153606’ ‘violin’ ‘1’]
[‘153605’ ‘violin’ ‘1’]
[‘153604’ ‘violin’ ‘1’]]
(Cluster: 1) Using majority voting as a criterion this cluster belongs to class: bassoon
Number of sounds in this cluster are: 22
sound-id, sound-class, classification decision
[[‘154336’ ‘bassoon’ ‘1’]
[‘154337’ ‘bassoon’ ‘1’]
[‘154335’ ‘bassoon’ ‘1’]
[‘154352’ ‘bassoon’ ‘1’]
[‘154344’ ‘bassoon’ ‘1’]
[‘154338’ ‘bassoon’ ‘1’]
[‘154339’ ‘bassoon’ ‘1’]
[‘154343’ ‘bassoon’ ‘1’]
[‘154342’ ‘bassoon’ ‘1’]
[‘154341’ ‘bassoon’ ‘1’]
[‘154340’ ‘bassoon’ ‘1’]
[‘154347’ ‘bassoon’ ‘1’]
[‘154346’ ‘bassoon’ ‘1’]
[‘154345’ ‘bassoon’ ‘1’]
[‘154353’ ‘bassoon’ ‘1’]
[‘154350’ ‘bassoon’ ‘1’]
[‘154349’ ‘bassoon’ ‘1’]
[‘154348’ ‘bassoon’ ‘1’]
[‘154351’ ‘bassoon’ ‘1’]
[‘61927’ ‘violin’ ‘0’]
[‘61928’ ‘violin’ ‘0’]
[‘153769’ ‘cello’ ‘0’]]
(Cluster: 2) Using majority voting as a criterion this cluster belongs to class: cello
Number of sounds in this cluster are: 23
sound-id, sound-class, classification decision
[[‘154334’ ‘bassoon’ ‘0’]
[‘61929’ ‘violin’ ‘0’]
[‘61930’ ‘violin’ ‘0’]
[‘153626’ ‘violin’ ‘0’]
[‘42252’ ‘cello’ ‘1’]
[‘42250’ ‘cello’ ‘1’]
[‘42251’ ‘cello’ ‘1’]
[‘42256’ ‘cello’ ‘1’]
[‘42257’ ‘cello’ ‘1’]
[‘42254’ ‘cello’ ‘1’]
[‘42255’ ‘cello’ ‘1’]
[‘42249’ ‘cello’ ‘1’]
[‘42248’ ‘cello’ ‘1’]
[‘42247’ ‘cello’ ‘1’]
[‘42246’ ‘cello’ ‘1’]
[‘42239’ ‘cello’ ‘1’]
[‘42260’ ‘cello’ ‘1’]
[‘42241’ ‘cello’ ‘1’]
[‘42243’ ‘cello’ ‘1’]
[‘42242’ ‘cello’ ‘1’]
[‘42253’ ‘cello’ ‘1’]
[‘42244’ ‘cello’ ‘1’]
[‘42259’ ‘cello’ ‘1’]]
Out of 60 sounds, 7 sounds are incorrectly classified considering that one cluster should ideally contain sounds from only a single class
You obtain a classification (based on obtained clusters and majority voting) accuracy of 88.33 percentage
2c. KNN find nearest neighbors
Which neighborhood or group does a sound belong to?
(using bad male vocal)
SA.classifySoundkNN(“qs/175454/175454/175454_2042115-lq.json”, “tmp”,13, descInput = [0,5,10])
===
from workspace…
First test: Use sounds by querying “saxophone”, tag=”alto-sax”
https://www.freesound.org/people/clruwe/sounds/119248/
I am using the same descriptors [0,2,9] that worked well in previous section. with K=3. Tried various values of K with this analysis and it always came out matching ‘violin’ which I think is correct.
In [26]: SA.classifySoundkNN(“qs/saxophone/119248/119248_2104336-lq.json”, “tmp”, 33, descInput = [0,2,9])
This sample belongs to class: violin
Out[26]: ‘violin’
Second test: I am trying out the freesound “similar sound” feature. Using one of the bassoon sounds I clicked “similar sounds” and chose a sound that was not a bassoon – “Bad Singer” (male).
http://freesound.org/people/sergeeo/sounds/175454/
Running the previous descriptors returned a match for violin. So I tried various other descriptors, and was able to get it to match bassoon consistently by using: [0,5,10] which are lowlevel.spectral_centroid.mean, lowlevel.spectral_contrast.mean.0, and lowlevel.mfcc.mean.0.
I honestly don’t know the best strategy for choosing these descriptors and tried to go with ones that seemed the least esoteric. The value of K does not seem to make any difference in the classification.
Here is the output
In [42]: SA.classifySoundkNN(“qs/175454/175454/175454_2042115-lq.json”, “tmp”,13, descInput = [0,5,10])
This sample belongs to class: bassoon
Out[42]: ‘bassoon’
2d. JSON analysis data for “bad voice” example…
#: cd ~/sms-tools/workspace/A9/qs/175454/175454
# cat 175454_2042115-lq.json | python -mjson.tool
3. acousticbrainz
(typical analysis page…) https://reactivemusic.net/?p=17641
4. Echonest acoustic analysis
fingerprinting and human factors like danceability…
- specification document: https://reactivemusic.net/?p=6276
- Max example: https://reactivemusic.net/?p=6296
- en_analyzer~ object https://reactivemusic.net/?p=6282
- Tristan Jehan’s Max/MSP externals http://web.media.mit.edu/~tristan/maxmsp.html
Randomness
continuum
random -> ordered (stochastic -> deterministic (for academics))
Does technology have a sound?
Can you add small bits of randomness?
- Can you detect randomness?
- How much repetition is enough?
Brain wiring diagram: https://reactivemusic.net/?p=17758
Christof Koch – check out this video at around 13:33 for about 2 minutes http://www.technologyreview.com/emtech/14/video/watch/christof-koch-hacking-the-soul/
With every technology, musicians figure out how to use it another way. Starting with stone tools, bow and arrow, and now computers.
Data science skills: https://reactivemusic.net/?p=17707
Car engine synthesizer
At the end of the class we revved the engine of a 2015 Golf TSI, connected to an engine sound simulator in Max, on Boylston street…
https://reactivemusic.net/?p=7643
Freesound
“Browse, download and share sounds”
By Frederic Font, Gerard Roma, and Xavier Serra. “Freesound technical demo.” Proceedings of the 21st ACM international conference on Multimedia. ACM, 2013.

Developer API: https://www.freesound.org/help/developers/
Music signal analysis
Low level features and timbre.
By Juan Pablo Bello at NYU
http://www.nyu.edu/classes/bello/MIR_files/timbre.pdf