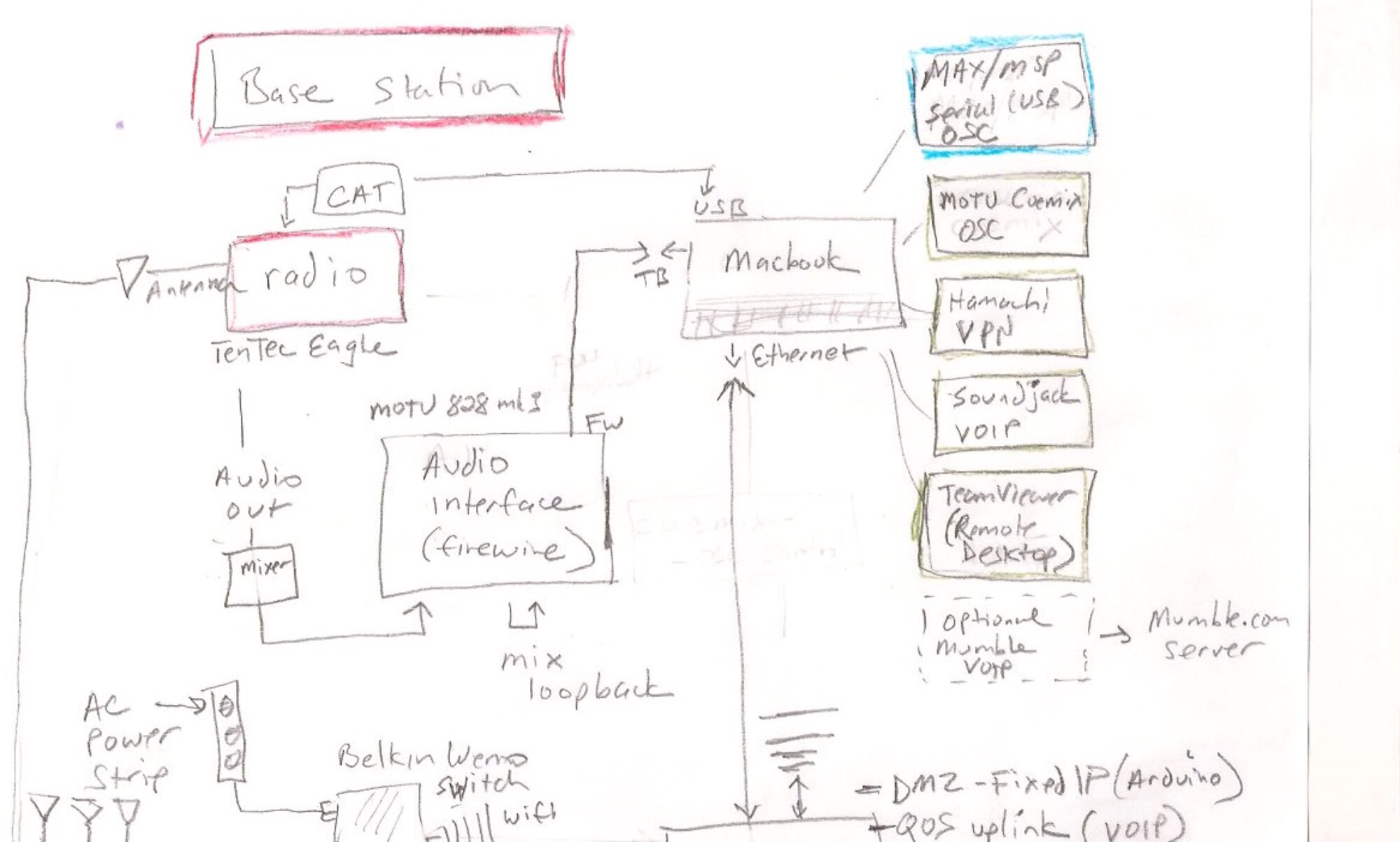
Notes for Ubuntu 14.04 LTS
Basic install:
1. use instructions at http://sdr.osmocom.org/trac/wiki/rtl-sdr
You will also need to install the following dependencies:
- git
- cmake
- make
- libusb-1.0
- sox (optional)
Two issues:
- rtlsdr device gets captured by OS, preventing application access
- Standard installation process doesn’t allow non-root users to use a device
To prevent OS from capturing device…
Set up a blacklist file as explained in this post:
https://groups.google.com/forum/#!msg/ultra-cheap-sdr/6_sSON94Azo/sOkhU81YINIJ
As the message suggests, there are two solutions. The quickest is to
simply unload the driver:
sudo rmmod dvb_usb_rtl28xxu rtl2832
Not sure whether “rtl2832” on the end there is required or not, but it
can’t hurt. This is only a temporary solution, as the driver will be
loaded again the next time you unplug and replug the USB device, so
you’ll have to run the command again.
If this works, and you don’t want to use the device for TV reception,
you can stop the module from ever being loaded, solving the problem
permanently. The exact method depends on your Linux distribution, but
for me (running Arch Linux) I create a file in /etc/modprobe.d with
a .conf extension (I called it “no-rtl.conf”) with these contents:
blacklist dvb_usb_rtl28xxu
blacklist rtl2832
blacklist rtl2830
Again not sure whether it’s necessary to blacklist all three of these
or just the first, but I was erring on the side of caution and chose to
list everything to do with the Realtek DVB device.
Once you have created this blacklist file, you may need to unload the
driver one last time if it was already running – the blacklist
prevents it from loading but doesn’t do anything if it’s already
running.
To allow non-root users to use the device…
Set up a udev rule as explained in this post:
http://www.instructables.com/id/rtl-sdr-on-Ubuntu/step3/Setup-udev-rules/
Next, you need to add some udev rules to make the dongle available for the non-root users. First you want to find the vendor id and product id for your dongle.
The way I did this was to run:
lsusb
The last line was the Realtek dongle:
Bus 001 Device 008: ID 0bda:2838 Realtek Semiconductor Corp.
The important parts are “0bda” (the vendor id) and “2838” (the product id).
Create a new file as root named /etc/udev/rules.d/20.rtlsdr.rules that contains the following line:
SUBSYSTEM==”usb”, ATTRS{idVendor}==”0bda”, ATTRS{idProduct}==”2838″, GROUP=”adm”, MODE=”0666″, SYMLINK+=”rtl_sdr”
With the vendor and product ids for your particular dongle. This should make the dongle accessible to any user in the adm group. and add a /dev/rtl_sdr symlink when the dongle is attached.
It’s probably a good idea to unplug the dongle, restart udev (sudo restart udev) and re-plug in the dongle at this point.