Web apps that talk.
By Eric Bidleman at HTML5 Rocks
http://updates.html5rocks.com/2014/01/Web-apps-that-talk—Introduction-to-the-Speech-Synthesis-API

Web apps that talk.
By Eric Bidleman at HTML5 Rocks
http://updates.html5rocks.com/2014/01/Web-apps-that-talk—Introduction-to-the-Speech-Synthesis-API
A presentation for Berklee BTOT 2015 http://www.berklee.edu/faculty
(KITT dashboard by Dave Metlesits)
The voice was the first musical instrument. Humans are not the only source of musical voices. Machines have voices. Animals too.

We instantly recognize people and animals by their voices. As an artist we work to develop our own voice. Voices contain information beyond words. Think of R2D2 or Chewbacca.
There is also information between words: “Palin Biden Silences” David Tinapple, 2008: http://vimeo.com/38876967
What’s in a voice?

Humans acting like synthesizers.
Teaching machines to talk.
Try the ‘say’ command (in Mac OS terminal), for example: say hello
Combining the energy of voice with musical instruments (convolution)
By Yamaha

(text + notation = singing)
Demo tracks: https://www.youtube.com/watch?v=QWkHypp3kuQ
Vocaloop device http://vocaloop.jp/ demo: https://www.youtube.com/watch?v=xLpX2M7I6og#t=24
Transformation
Pitch transposing a baby https://reactivemusic.net/?p=2458
Autotune: “T-Pain effect” ,(I-am-T-Pain bySmule), “Lollipop” by Lil’ Wayne. “Woods” by Bon Iver https://www.youtube.com/watch?v=1_cePGP6lbU
by Matthew Davidson
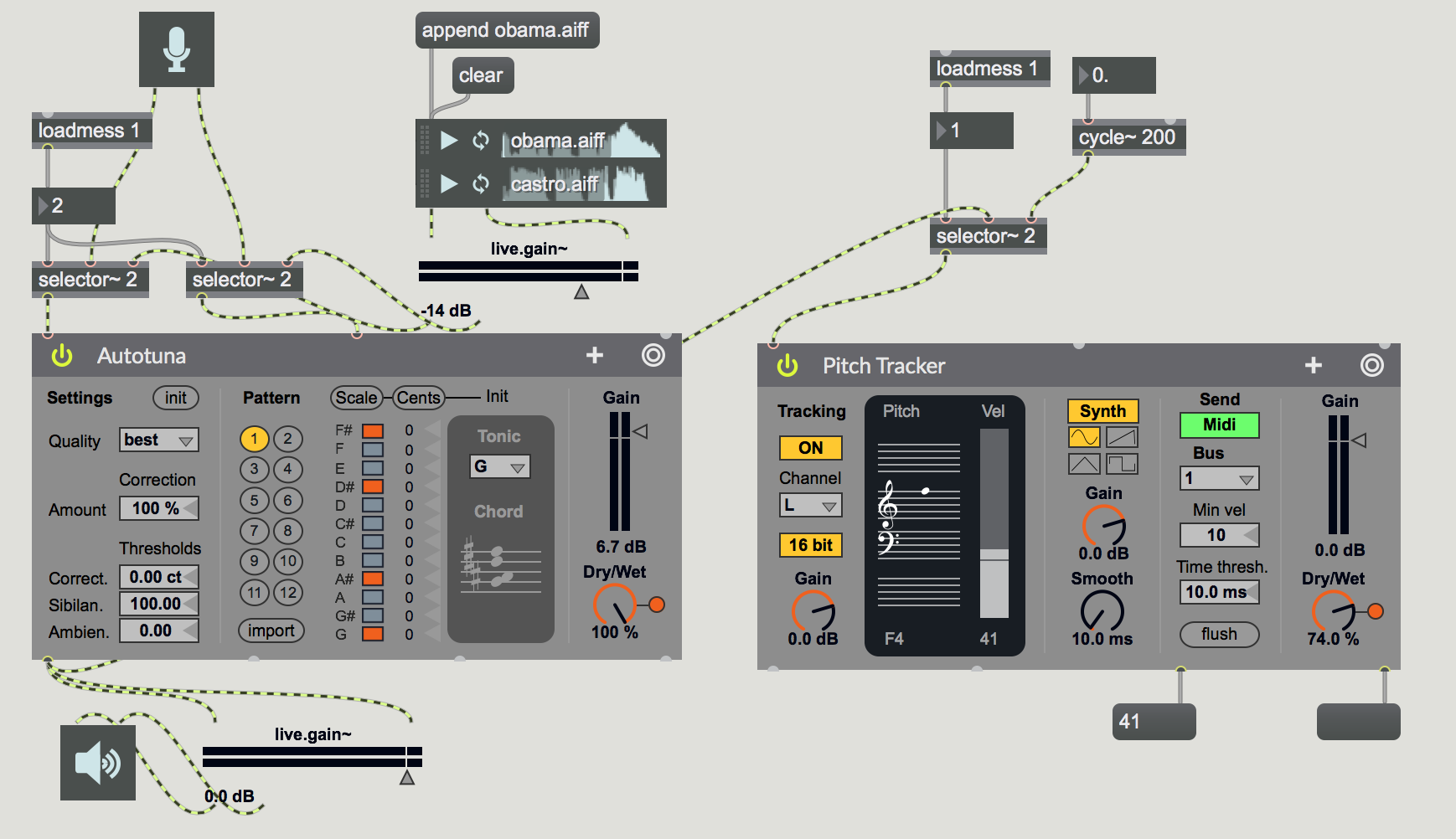
Local file: max-teaching-examples/autotuna-test.maxpat
by Katja Vetter
http://www.katjaas.nl/slicejockey/slicejockey.html
Autocorrelation: (helmholtz~ Pd external) “Helmholtz finds the pitch” http://www.katjaas.nl/helmholtz/helmholtz.html
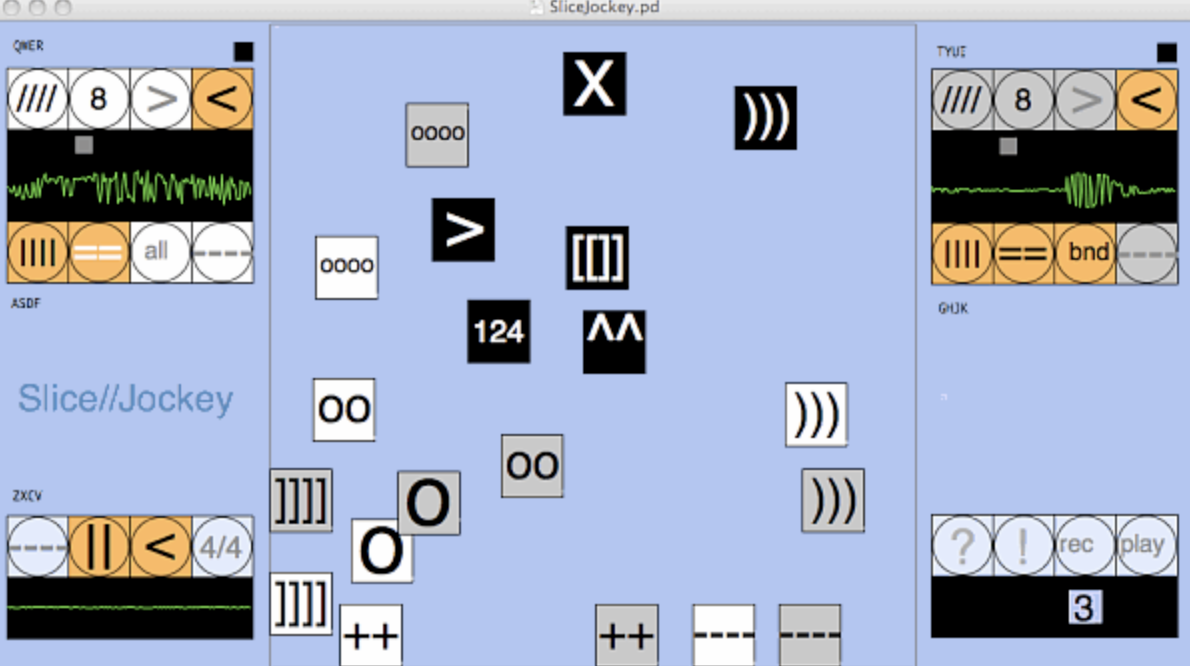
(^^ is input pitch, preset #9 is normal)
Disassembling time into very small pieces
Adapted from Andy Farnell, “Designing Sound”
https://reactivemusic.net/?p=11385 Download these patches from: https://github.com/tkzic/max-projects folder: granular-timestretch

…coming soon
Changing sound into pictures and back into sound
by Tadej Droljc
https://reactivemusic.net/?p=16887
(Example of 3d speech processing at 4:12)
local file: SSP-dissertation/4 – Max/MSP/Jitter Patch of PV With Spectrogram as a Spectral Data Storage and User Interface/basic_patch.maxpat
Try recording a short passage, then set bound mode to 4, and click autorotate
Understanding the meaning of speech
A conversation with a robot in Max
https://reactivemusic.net/?p=9834

Google speech uses neural networks, statistics, and large quantities of data.
Changes in the environment reflected by sound
“You can talk to the animals…”
Pig creatures example: http://vimeo.com/64543087
What about Jar Jar Binks?
The sound changes but the words remain the same.
The Speech accent archive https://reactivemusic.net/?p=9436
We are always singing.
by Xavier Serra and UPF
Harmonic Model Plus Residual (HPR) – Build a spectrogram using STFT, then identify where there is strong correlation to a tonal harmonic structure (music). This is the harmonic model of the sound. Subtract it from the original spectrogram to get the residual (noise).
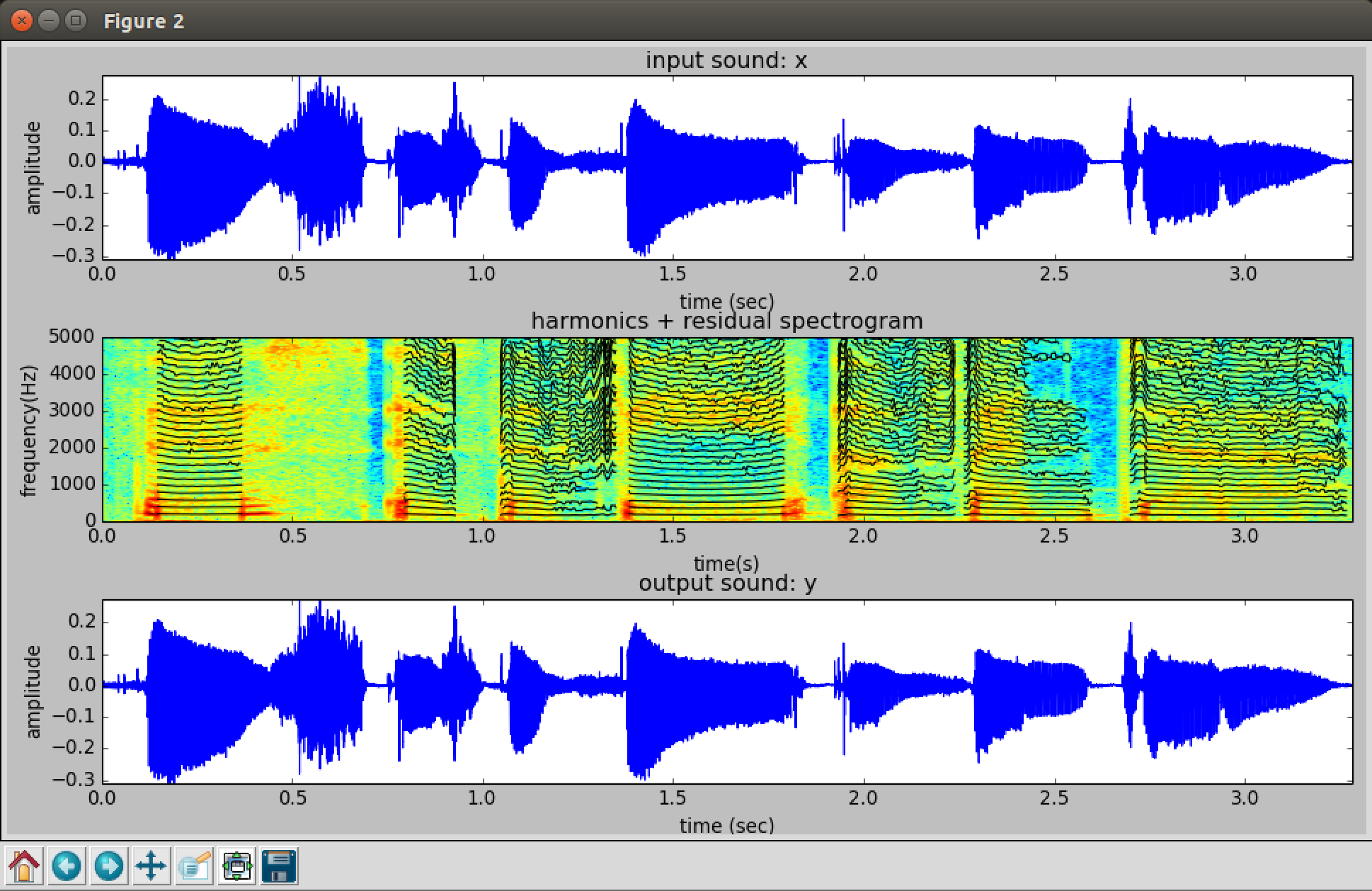
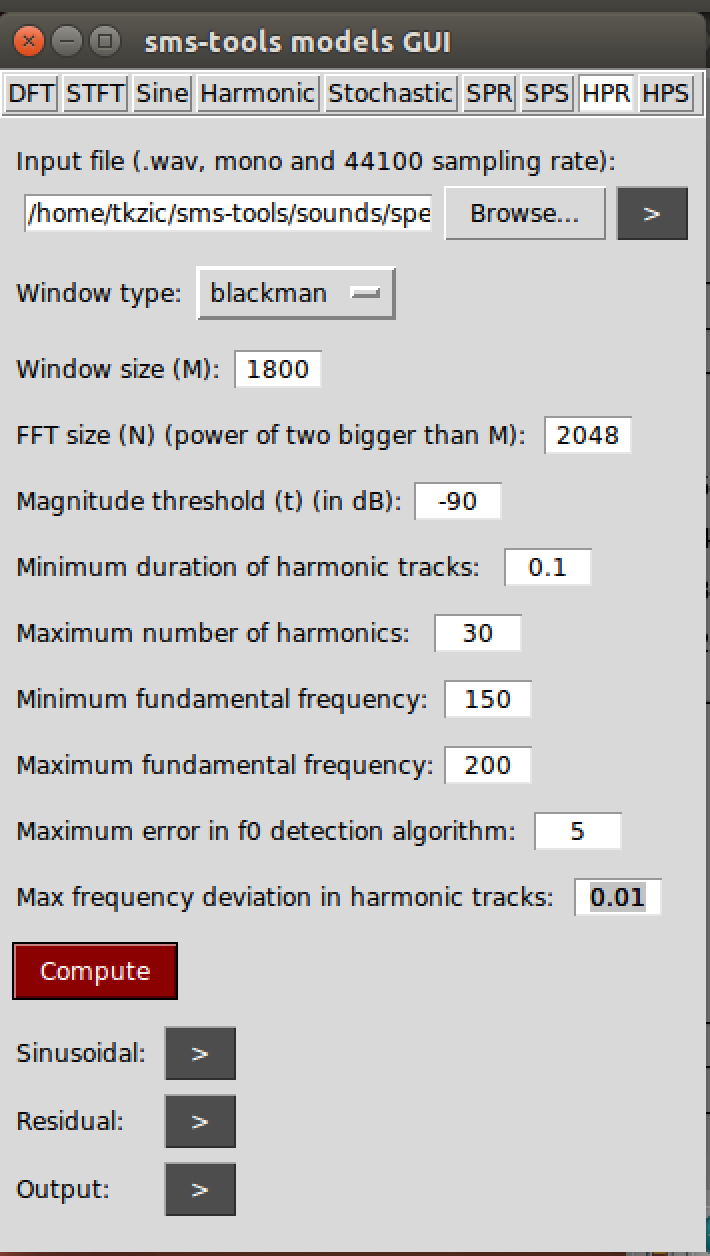
Settings for above example:
Acoustic Brainz: (typical analysis page) https://reactivemusic.net/?p=17641
Essentia (open source feature detection tools) https://github.com/MTG/essentia
Freesound (vast library of sounds): https://www.freesound.org – look at “similar sounds”
A sad thought
This method was used to send secret messages during world war 2. Its now used in cell phones to get rid of echo. Its also used in noise canceling headphones.
https://reactivemusic.net/?p=8879

max-projects/phase-cancellation/phase-cancellation-example.maxpat
What is not left and not right?
Ableton Live – utility/difference device: https://reactivemusic.net/?p=1498 (Allison Krause example)
Local file: Ableton-teaching-examples/vocal-eliminator
Questions
update 5/17/2014: The key in the post below is now disabled. Trying this one: AIzaSyBOti4mM-6x9WDnZIjIeyEU21OpBXqWBgw
It worked for now – but I will probably need to get a real key… and add instructions for inserting the key into the patches: robot_conversation5.maxpat and speech-to-google-text-api5.maxpat
Basic instructions are
v1 API of Google Speech broke a few days ago.
Here is an example of how to run v2. https://github.com/gillesdemey/google-speech-v2
I have updated the Max patches in the Internet Sensors project. https://github.com/tkzic/internet-sensors
This version of the API produces malformed JSON responses.
Here’s an example using curl:
curl -v -i -X POST -H “Content-Type:audio/x-flac; rate=16000” -T /tmp/tweet.flac “https://www.google.com/speech-api/v2/recognize?xjerr=1&client=chromium&lang=en-US&maxresults=10&pfilter=0&xjerr=1&key=AIzaSyCnl6MRydhw_5fLXIdASxkLJzcJh5iX0M4”
Instructions for getting a real key… http://www.chromium.org/developers/how-tos/api-keys
Note: Need to look at the double buffering methods in the Max patches to make sure they are handling various sample rates properly. I think they may be optimized for 44.1 KHz
update 6/2014 – Now part of the Internet sensors projects: https://reactivemusic.net/?p=5859
original post
They can talk with each other… sort of.
Last spring I made a project that lets you talk with chatbots using speech recognition and synthesis. https://reactivemusic.net/?p=4710.
Yesterday I managed to get two instances of this program, running on two computers, using two chatbots, to talk with each other, through the air. Technical issues remain (see below). But there were moments of real interaction.
In the original project, a human pressed button in Max to start and stop recording speech. This has been automated. The program detects and records speech, using audio level sensing. The auto-recording sensor turns on a switch when the level hits a threshold, and turns off after a period of silence. Threshold level and duration of silence can be adjusted by the user. There is also a feedback gate that shuts off auto-record while the computer is converting speech to text, and ‘speaking’ a reply.

This project brings together several examples of API programming with Max. The pandorabots.api patch contains an example of using curl to generate an XML response file, then converts XML to JSON using a Python script. The resulting JSON file is read into Max and parsed using the [js] object.
Here is an audio recording of my conversation (using Max) with a text chatbot named ‘Chomsky’
My voice gets recorded by Max then converted to text by the Google speech-api.
The text is passed to the Pandorabots API. The chatbot response gets spoken by the aka.speech external which uses the Mac OS built-in text-to-speech system.
Note: The above recording was processed with a ‘silence truncate’ effect because there were 3-5 second delays between responses. In realtime it has the feel of the Houston/Apollo dialogs.
pandorabots-api.maxpat (which handles chatbot responses) gets text input from speech-to-google-text-api2.maxpat – a patch that converts speech to text using the Google speech-API.
https://reactivemusic.net/?p=4690
The output (responses from chatbot) get sent to twitter-search-to-speech2.maxpat which “speaks” using the Mac OS text-to-speech program using the aka.speech external.
Max
The files for this project can be downloaded from the intenet-sensors archive at github
Speech recognition:
http://fennb.com/fast-free-speech-recognition-using-googles-in
Here’s a link to the manual for sox (audio converter)
This is an example of the curl command to run from the command line
curl \ --data-binary @test.flac \ --header 'Content-type: audio/x-flac; rate=16000' \ 'https://www.google.com/speech-api/v1/recognize?xjerr=1&client=chromium&pfilter=2&lang=en-US&maxresults=6'
(update 6/2014): its easier to use the Google speech-api by calling it from curl. See recent examples at: https://reactivemusic.net/?p=4690
original post:
from Luke Hall in the c74 forum:
http://cycling74.com/forums/topic.php?id=18403
I’ve used Macspeech Dictate in this way. In fact it uses the same speech recognition engine as Dragon Naturally Speaking, it works very well but you could potentially run into the same problems as CJ described above.
Another way to achieve this on a mac is using the built in voice recognition and applescripts and extra suites, which is an applescript extension that extends the range of what you can do, including letting you send key presses.
1. Turn on “speakable items” from system preferences > speech > speech recognition.
2. Open max.
3. Open script editor and write a script like this:
tell application “MaxMSP” to activate
tell application “Extra Suites”
ES type key “1”
end tell
4. Save it in library > speech > speakable items > application speakable items > maxmsp and name the file whatever you want the voice command to be, for example “press one”
6. Now on the floating speech icon click the down arrow at the bottom and “open speech commands window”. With max as the front-most application check that the commands you just saved as applescripts have appeared in the maxmsp folder.
7. Now simply hook up a [key] object in max, press “escape” (or whichever key you have set up to turn speech recognition on) and say “press one” and you should have [key] spit out “49”!
Sorry about the length explanation I hope it makes sense to you and gives you another possible (and cheaper!) method of obtaining you goals.
Oh and the applescript extension can be downloaded from: http://www.kanzu.com/
lh
Chrome now includes online speech recognition
Max auto-tweeting text-to-speech-to-text
By Aaron Oppenheim
http://www.aaronoppenheim.com/projects/twittererer