nothing-detector.maxpat (for tracking progress of html request)
authorization
none required
instructions
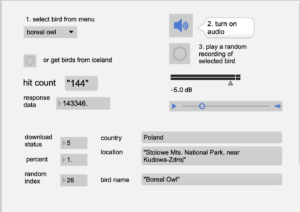
Open the Max patch: bird-call4.maxpat
Select a bird from the menu. Wait a few seconds. If the hit-counter increases above zero then the search was successful.
Click the button to start audio.
Click the button to play a random recording from the query
notes
There are two html queries. The first query retrieves an array of recording records for a selected bird. The second query downloads the .mp3 file with the actual recording.
The patch uses [dict] and [maxurl] to format execute the first query. Then it uses [jit.uldl] to download the .mp3 file.
I loaded the result file from this query into a max patch: JSON_readwrite-nyt-test and printed out the title and body of the first article returned.
There are examples in the above link and explanation of using ‘facets’ which give you stuff like counts of articles and mentions of things like corporation names & other common things. Also some logic tricks for doing complex queries.
update: this conversion may be built into Max 6.1.7… [js]
For now I am using the following method:
Write xml using jit.textfile
use aka.shell to convert xml to json using python script xml2json.py (modified header)
read the json file in using method in JSON_Readwrite.maxhelp
Its not elegant but it works on the MAC – without installing additional software, like node.js and all of its packages.
update: 3 weeks later. Have been using the above method and also calling curl from aka.shell – writing XML files to /tmp – Then following steps 2 and 3 above. Works fine.