
“Partition n observations into k clusters in which each observation belongs to the cluster with the nearest mean, serving as a prototype of the cluster.”
At Wikipedia
http://en.wikipedia.org/wiki/K-means_clustering
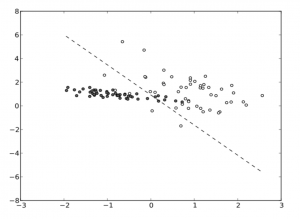
Some of these points are more like the others