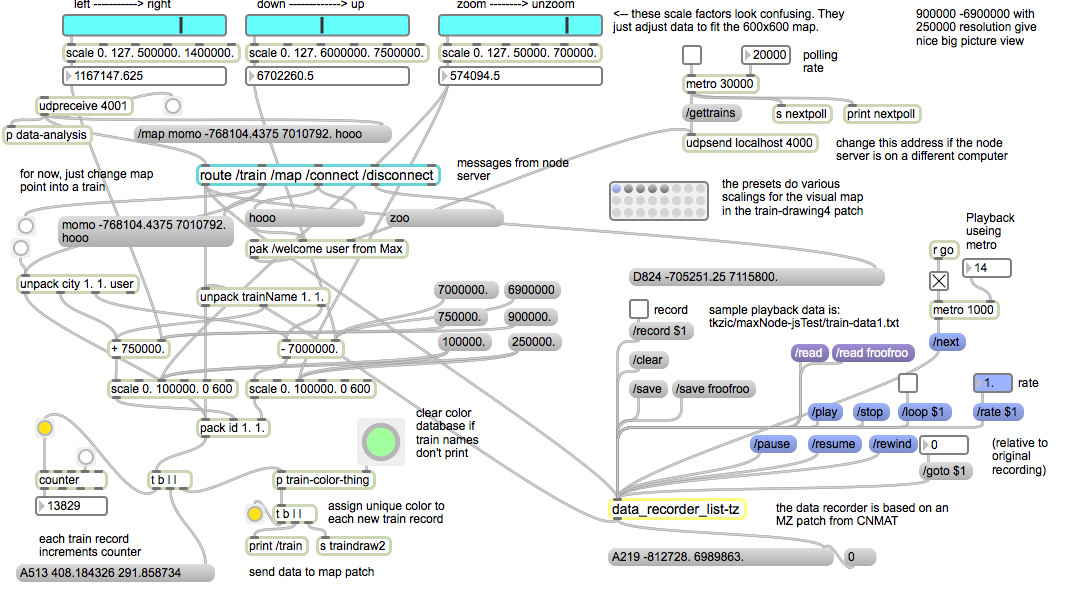
Machine learning library for Max and Pd.
By Ali Momeni and Jamie Bullock
https://github.com/cmuartfab/ml-lib
Machine learning library for Max and Pd.
By Ali Momeni and Jamie Bullock
https://github.com/cmuartfab/ml-lib
For the Echonest API track profile response.
By Jason Sundram at Running With Data
http://runningwithdata.com/post/1321504427/danceability-and-energy
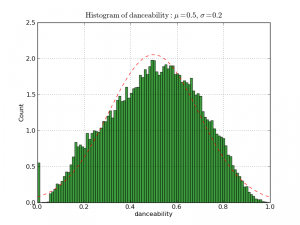
Get track analysis data for your music using the Echonest API.
The track analysis includes summary information about a track including tempo, key signature, time signature mode, danceability, loudness, liveness, speechinesss, acousticness and energy along with detailed information about the song structure (sections) beat structure (bars, beats tatums) and detailed info about timbre, pitch and loudness envelope (segment).
track API documentation: http://developer.echonest.com/docs/v4/track.html
Its a two (or three) step process. Here’s an example of how to upload your track and get an audio summary, using curl from the command line in Mac OS. Note, you will need to register with Echonest to get a developer API key here: http://developer.echonest.com/raw_tutorials/register.html
Note that the path to the filename needs to be complete or relative to the working directory. Also, in this example there was no metadata identifying the title of the song. You may want to change this before uploading. Replace the API key with your key.
curl -F “api_key=TV2C30KWEJDKVIT9P” -F “filetype=mp3” -F “track=@/Users/tkzic/internetsensors/echo-nest/bowlingnight.mp3” “http://developer.echonest.com/api/v4/track/upload”
Here is the response returned:
{“response”: {“status”: {“version”: “4.2”, “code”: 0, “message”: “Success”}, “track”: {“status”: “pending”, “artist”: “Tom Zicarelli”, “title”: “”, “release”: “”, “audio_md5”: “7edc05a505c4aa4b8ff87ba40b8d7624”, “bitrate”: 128, “id”: “TRLFXWY14ACC02F24C”, “samplerate”: 44100, “md5”: “78ccac72a2b6c1aed1c8e059983ce7c7”}}}
Here’s the query to get the analysis – using the ID returned by the previous call. Replace the API key with your key.
curl “http://developer.echonest.com/api/v4/track/profile?api_key=TV2C30KYGHTUVIT9P&format=json&id=TRLFXWY14ACC02F24C&bucket=audio_summary”
Here is the response – which also contains a URL that you can use to get more detailed segment based acoustic analysis of the track.
{
“response”: { “status”: { “code”: 0, “message”: “Success”, “version”: “4.2” }, “track”: { “analyzer_version”: “3.2.2”, “artist”: “Tom Zicarelli”, “audio_md5”: “7edc05a505c4aa4b8ff87ba40b8d7624”, “audio_summary”: { “acousticness”: 0.64550727753299, “analysis_url”: “http://echonest-analysis.s3.amazonaws.com/TR/TRLFXWY14ACC02F24C/3/full.json?AWSAccessKeyId=AKIAJRDFEY23UEVW42BQ&Expires=1420763215&Signature=OLqYwvuzVmAqp1xLTi5x4CsYJuE%3D”, “danceability”: 0.5680872294350238, “duration”: 245.91673, “energy”: 0.19974462311717034, “instrumentalness”: 0.8089125726216321, “key”: 11, “liveness”: 0.10906007889455183, “loudness”: -25.331, “mode”: 1, “speechiness”: 0.03294587631927559, “tempo”: 93.689, “time_signature”: 4, “valence”: 0.43565861274829504 }, “bitrate”: 128, “id”: “TRLFXWY14ACC02F24C”, “md5”: “78ccac72a2b6c1aed1c8e059983ce7c7”, “samplerate”: 44100, “status”: “complete” } } }
Use the analysis_url returned by the previous request. Note that it expires a few minutes after the request. But you can always re-run the audio_profile request to get a new analysis_url
curl “http://echonest-analysis.s3.amazonaws.com/TR/TRLFXWY14ACC02F24C/3/full.json?AWSAccessKeyId=AKIASVIFEY23UEGE42BQ&Expires=1420763215&Signature=OLqYwvuzVmAqp1xLTi5x4CsYJuE%3D”
The analysis result is too large to display here. For more information, get the Echonest Analyze Documentation: http://developer.echonest.com/docs/v4/_static/AnalyzeDocumentation.pdf
“Intensely pleasurable responses to music correlate with activity in brain regions implicated in reward and emotion.”
By Anne J. Blood* and Robert J. Zatorre at Montreal Neurological Institute, McGill University (2001)
http://www.pnas.org/content/98/20/11818.full
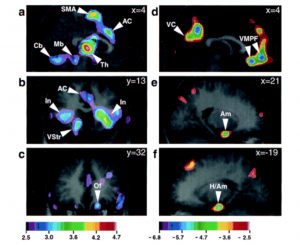
Also in “Berklee Today”, by Sarah Godcher: http://www.berklee.edu/bt/133/bb_neurology.html
“Results of the chills study also showed decreased activity in the areas of the brain that process danger and anxiety. “This says to me,” continued Blood, “that in order to experience this kind of euphoria, the part of the brain [that responds to danger] has to shut down. You can’t be euphoric and scared at the same time.”
The study also revealed that the brain processes consonant and dissonant sounds in very different ways. Dissonant sounds affected areas of the brain involving memory and anxiety, while consonant sounds stimulated areas involved in pleasant emotional responses. The results of Blood’s study may be validating through science what composers and performers of music have known for centuries.
Blood hastened to add that music’s ability to produce the chills is entirely subjective. All 10 of the subjects in the study selected classical music, but jazz and rock also can affect listeners just as powerfully, she said. Proof of this subjectivity can be found in a person’s response to music they did not select themselves. As each individual listened to a piece of music selected by one of the other nine subjects, “no one responded similarly to someone else’s music,” Blood said.
A significant aspect of Blood’s findings is that almost all of the brain’s response to music takes place at the subcortical level, that is in nerve centers below the cerebral cortex, which is the region of the brain where abstract thought occurs. Our brains process music, therefore, without really thinking about it. “It looks like the emotional part of music is getting at something more fundamental than cognition,” Blood explained.”
A Soundcloud April fools prank becomes reality.
A research paper by Karthik Yadati, Martha Larson, Cynthia C. S. Liem, Alan Hanjalic at Delft University of Technology (2014)
http://www.terasoft.com.tw/conf/ismir2014/proceedings/T026_297_Paper.pdf
The Soundcloud prank (2013)
http://www.attackmagazine.com/news/soundcloud-when-april-fools-day-pranks-go-wrong/
“Browse, download and share sounds”
By Frederic Font, Gerard Roma, and Xavier Serra. “Freesound technical demo.” Proceedings of the 21st ACM international conference on Multimedia. ACM, 2013.

Developer API: https://www.freesound.org/help/developers/
Low level features and timbre.
By Juan Pablo Bello at NYU
http://www.nyu.edu/classes/bello/MIR_files/timbre.pdf
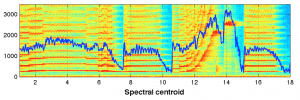
Music and audio analysis at the sample level.
By Tristan Jehan and David DesRoches at The Echo Nest
http://docs.echonest.com.s3-website-us-east-1.amazonaws.com/_static/AnalyzeDocumentation.pdf
