Translates back and forth from English to Japanese seeking equilibrium.

By Sami Lemmetty at University of Helsinki, 1999
http://research.spa.aalto.fi/publications/theses/lemmetty_mst/index.html
Includes links to Speech synthesis demonstration CD http://research.spa.aalto.fi/publications/theses/lemmetty_mst/appa.html
In Ableton Live
By Thavius Beck at Dubspot
by soundwavescience
A presentation for Berklee BTOT 2015 http://www.berklee.edu/faculty
(KITT dashboard by Dave Metlesits)
The voice was the first musical instrument. Humans are not the only source of musical voices. Machines have voices. Animals too.

We instantly recognize people and animals by their voices. As an artist we work to develop our own voice. Voices contain information beyond words. Think of R2D2 or Chewbacca.
There is also information between words: “Palin Biden Silences” David Tinapple, 2008: http://vimeo.com/38876967
What’s in a voice?

Humans acting like synthesizers.
Teaching machines to talk.
Try the ‘say’ command (in Mac OS terminal), for example: say hello
Combining the energy of voice with musical instruments (convolution)
By Yamaha

(text + notation = singing)
Demo tracks: https://www.youtube.com/watch?v=QWkHypp3kuQ
Vocaloop device http://vocaloop.jp/ demo: https://www.youtube.com/watch?v=xLpX2M7I6og#t=24
Transformation
Pitch transposing a baby https://reactivemusic.net/?p=2458
Autotune: “T-Pain effect” ,(I-am-T-Pain bySmule), “Lollipop” by Lil’ Wayne. “Woods” by Bon Iver https://www.youtube.com/watch?v=1_cePGP6lbU
by Matthew Davidson
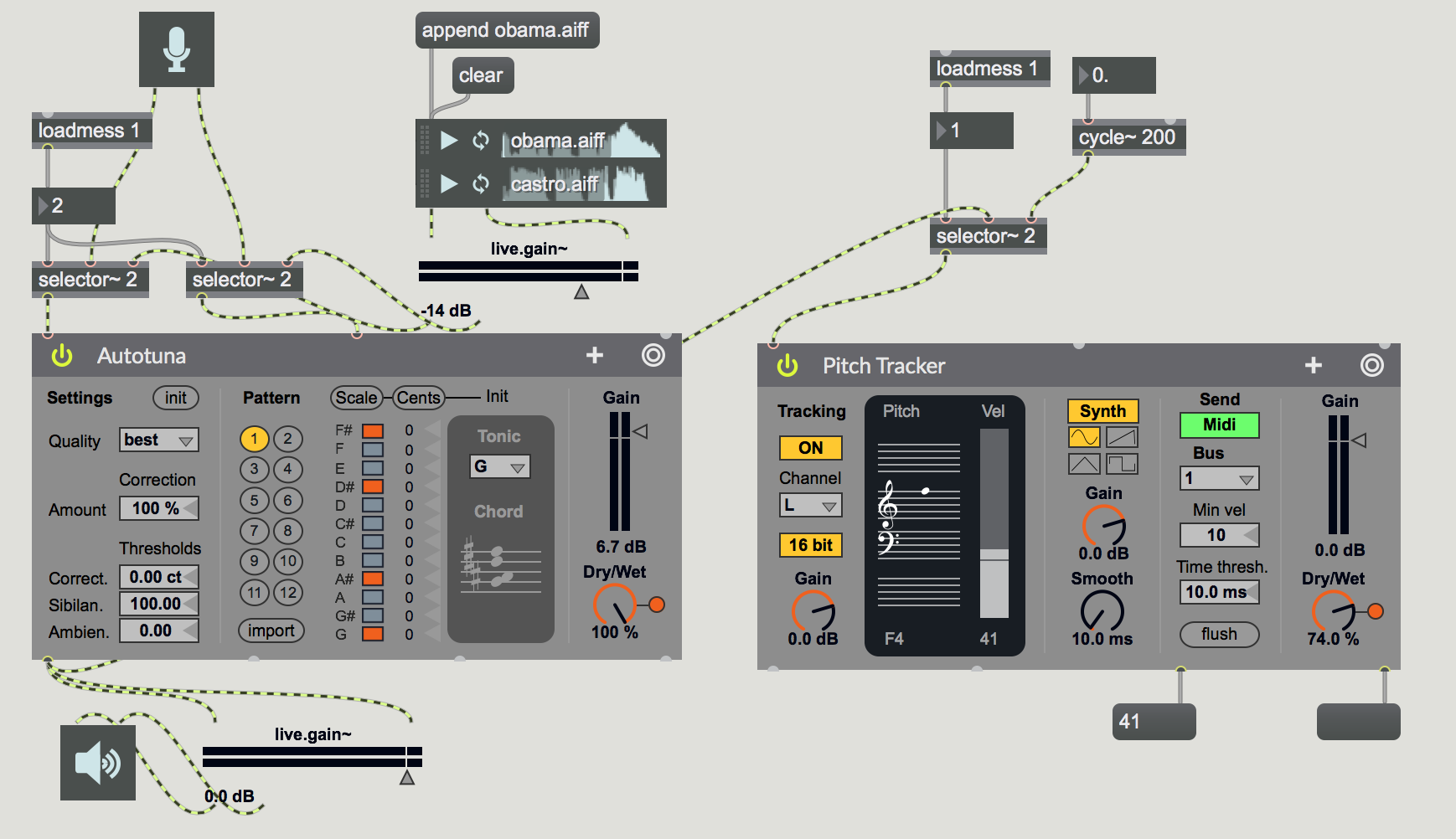
Local file: max-teaching-examples/autotuna-test.maxpat
by Katja Vetter
http://www.katjaas.nl/slicejockey/slicejockey.html
Autocorrelation: (helmholtz~ Pd external) “Helmholtz finds the pitch” http://www.katjaas.nl/helmholtz/helmholtz.html
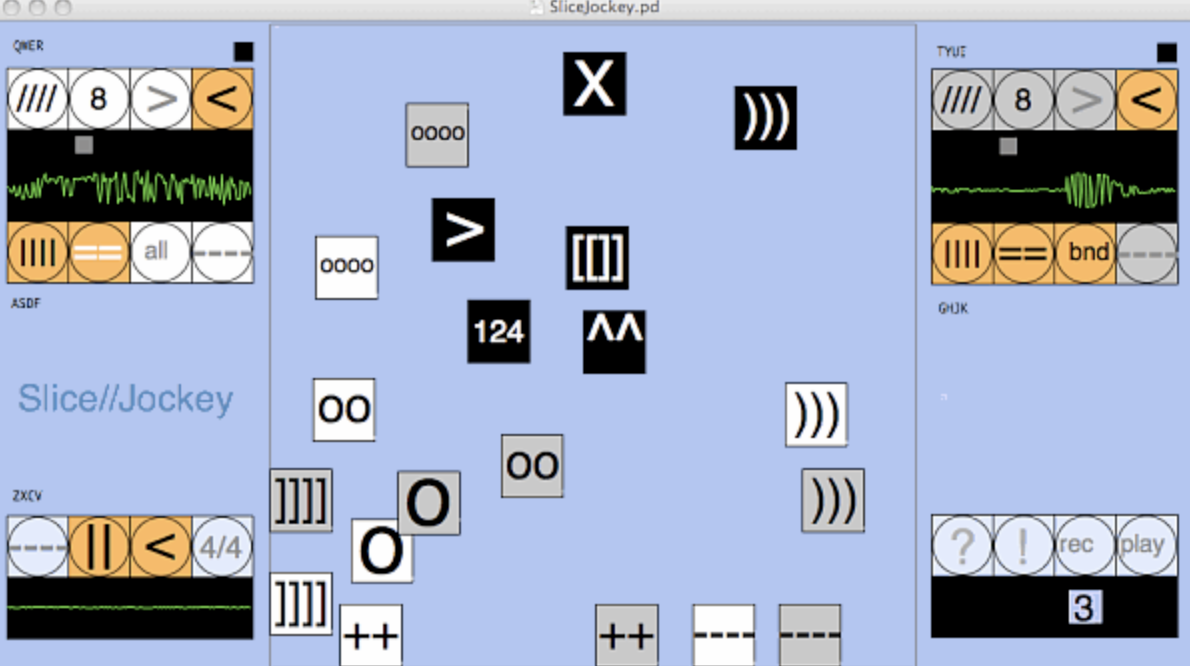
(^^ is input pitch, preset #9 is normal)
Disassembling time into very small pieces
Adapted from Andy Farnell, “Designing Sound”
https://reactivemusic.net/?p=11385 Download these patches from: https://github.com/tkzic/max-projects folder: granular-timestretch

…coming soon
Changing sound into pictures and back into sound
by Tadej Droljc
https://reactivemusic.net/?p=16887
(Example of 3d speech processing at 4:12)
local file: SSP-dissertation/4 – Max/MSP/Jitter Patch of PV With Spectrogram as a Spectral Data Storage and User Interface/basic_patch.maxpat
Try recording a short passage, then set bound mode to 4, and click autorotate
Understanding the meaning of speech
A conversation with a robot in Max
https://reactivemusic.net/?p=9834

Google speech uses neural networks, statistics, and large quantities of data.
Changes in the environment reflected by sound
“You can talk to the animals…”
Pig creatures example: http://vimeo.com/64543087
What about Jar Jar Binks?
The sound changes but the words remain the same.
The Speech accent archive https://reactivemusic.net/?p=9436
We are always singing.
by Xavier Serra and UPF
Harmonic Model Plus Residual (HPR) – Build a spectrogram using STFT, then identify where there is strong correlation to a tonal harmonic structure (music). This is the harmonic model of the sound. Subtract it from the original spectrogram to get the residual (noise).
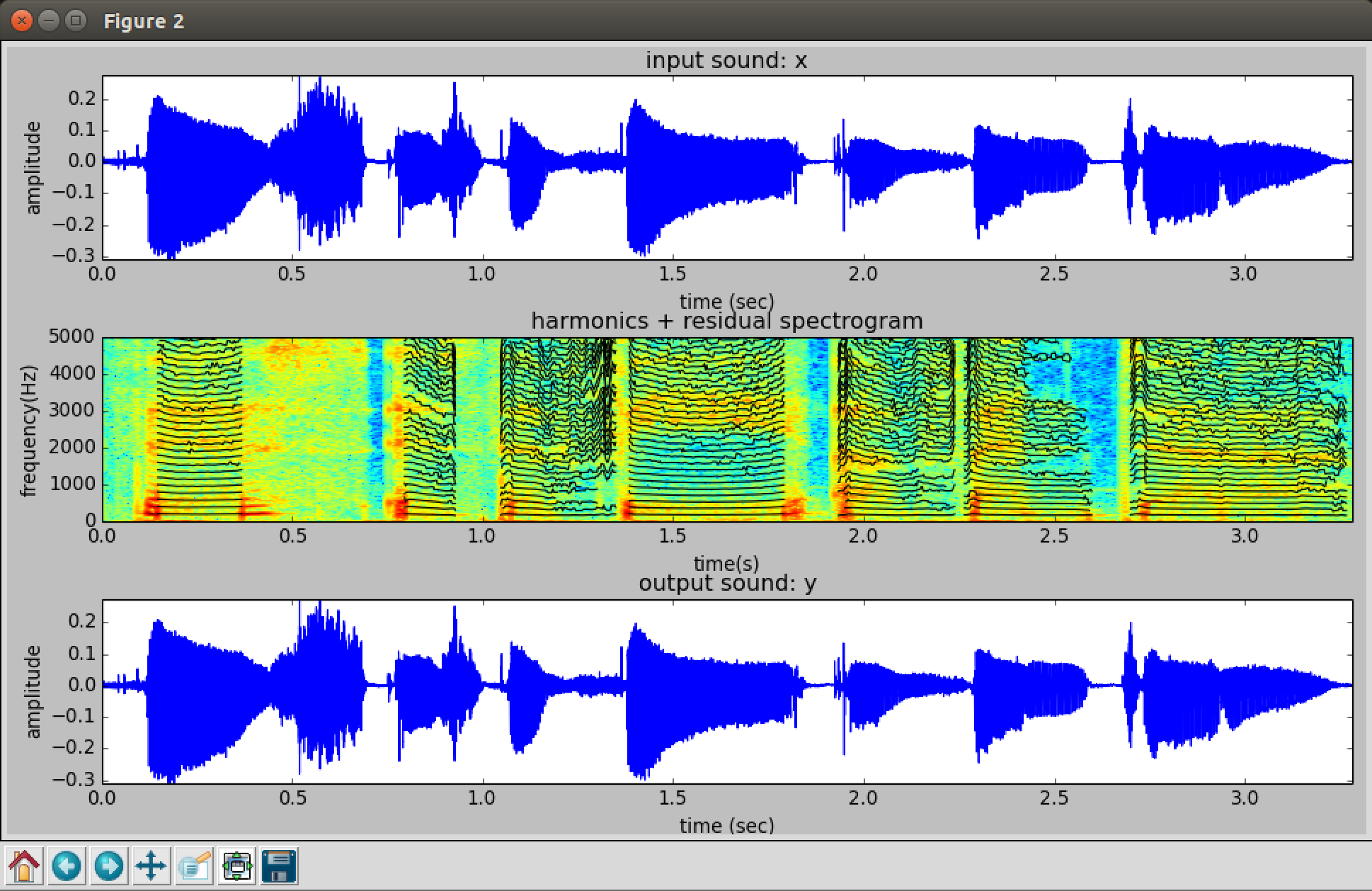
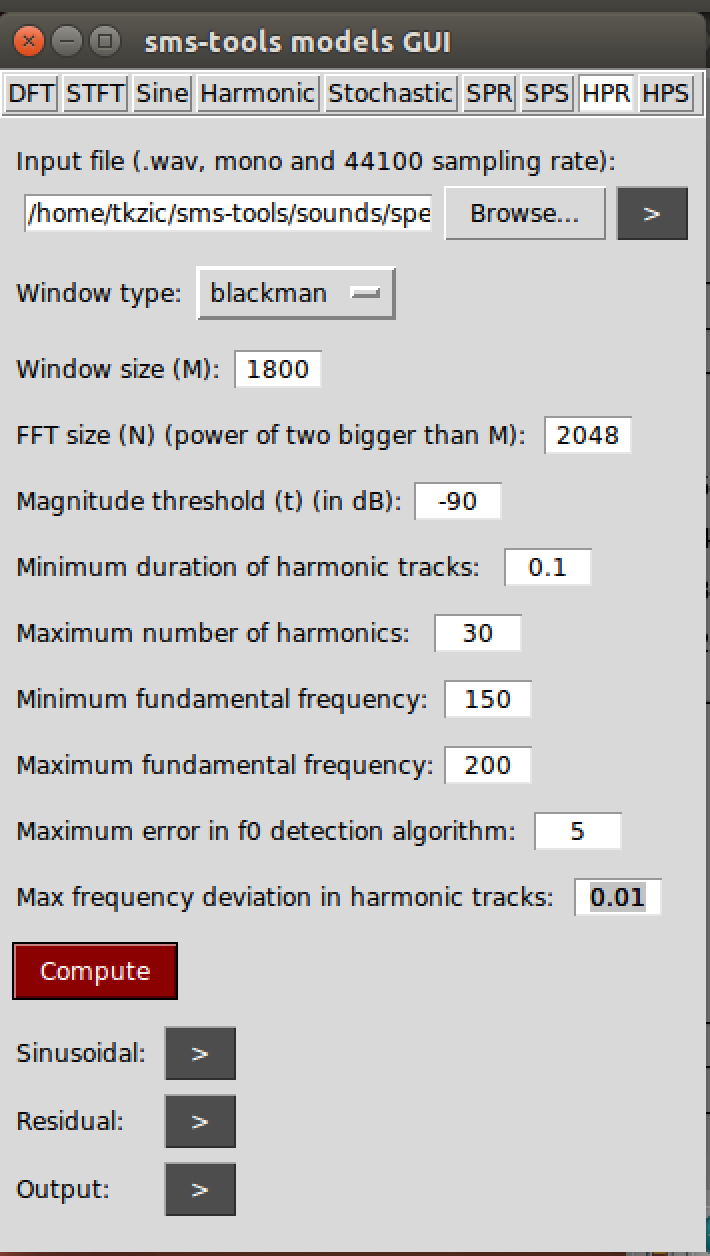
Settings for above example:
Acoustic Brainz: (typical analysis page) https://reactivemusic.net/?p=17641
Essentia (open source feature detection tools) https://github.com/MTG/essentia
Freesound (vast library of sounds): https://www.freesound.org – look at “similar sounds”
A sad thought
This method was used to send secret messages during world war 2. Its now used in cell phones to get rid of echo. Its also used in noise canceling headphones.
https://reactivemusic.net/?p=8879

max-projects/phase-cancellation/phase-cancellation-example.maxpat
What is not left and not right?
Ableton Live – utility/difference device: https://reactivemusic.net/?p=1498 (Allison Krause example)
Local file: Ableton-teaching-examples/vocal-eliminator
Questions
In the frequency domain
By Dude837
http://www.otherbirds.com/tutorials/4-vocoder.zip
All tutorials: http://www.otherbirds.com/tutorials
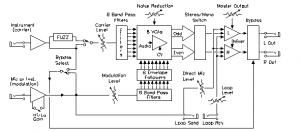
Using the fffb~ object in Max – with feedback and vocoder effects.
By Peter Elsea
http://peterelsea.com/Maxtuts_msp/ThirdOct.pdf
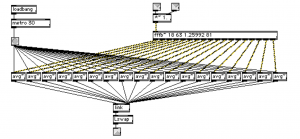
Semi-Parametric Synthesis of Speaker-Like Laughter
By Greg Beller at IRCAM, 2008
http://www.gregbeller.com/2008/06/laughter-synthesis/
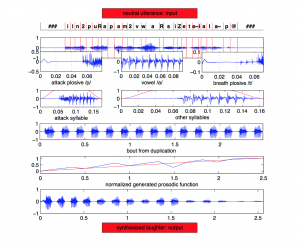
a system to automatically detect laughter from acoustic features of audio using neural networks.
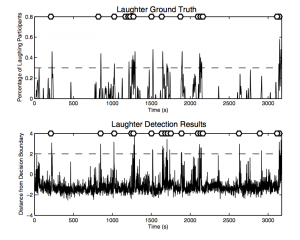
By Mary Knox at Berkeley
https://www.icsi.berkeley.edu/pubs/speech/laughter_v10.pdf
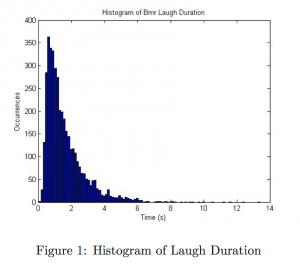
A system to automatically detect laughter events.
By Lyndon S. Kennedy and Daniel P.W. Ellis at Columbia University and ICSI
http://www.ee.columbia.edu/~lyndon/pubs/nistrt2004-laughter.pdf