
By Chris Woodford at Explain That Stuff, 2014
http://www.explainthatstuff.com/how-speech-synthesis-works.html
By Chris Woodford at Explain That Stuff, 2014
http://www.explainthatstuff.com/how-speech-synthesis-works.html
Web apps that talk.
By Eric Bidleman at HTML5 Rocks
http://updates.html5rocks.com/2014/01/Web-apps-that-talk—Introduction-to-the-Speech-Synthesis-API

By Sami Lemmetty at University of Helsinki, 1999
http://research.spa.aalto.fi/publications/theses/lemmetty_mst/index.html
Includes links to Speech synthesis demonstration CD http://research.spa.aalto.fi/publications/theses/lemmetty_mst/appa.html
For the Echonest API track profile response.
By Jason Sundram at Running With Data
http://runningwithdata.com/post/1321504427/danceability-and-energy
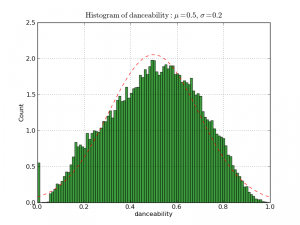
Get track analysis data for your music using the Echonest API.
The track analysis includes summary information about a track including tempo, key signature, time signature mode, danceability, loudness, liveness, speechinesss, acousticness and energy along with detailed information about the song structure (sections) beat structure (bars, beats tatums) and detailed info about timbre, pitch and loudness envelope (segment).
track API documentation: http://developer.echonest.com/docs/v4/track.html
Its a two (or three) step process. Here’s an example of how to upload your track and get an audio summary, using curl from the command line in Mac OS. Note, you will need to register with Echonest to get a developer API key here: http://developer.echonest.com/raw_tutorials/register.html
Note that the path to the filename needs to be complete or relative to the working directory. Also, in this example there was no metadata identifying the title of the song. You may want to change this before uploading. Replace the API key with your key.
curl -F “api_key=TV2C30KWEJDKVIT9P” -F “filetype=mp3” -F “track=@/Users/tkzic/internetsensors/echo-nest/bowlingnight.mp3” “http://developer.echonest.com/api/v4/track/upload”
Here is the response returned:
{“response”: {“status”: {“version”: “4.2”, “code”: 0, “message”: “Success”}, “track”: {“status”: “pending”, “artist”: “Tom Zicarelli”, “title”: “”, “release”: “”, “audio_md5”: “7edc05a505c4aa4b8ff87ba40b8d7624”, “bitrate”: 128, “id”: “TRLFXWY14ACC02F24C”, “samplerate”: 44100, “md5”: “78ccac72a2b6c1aed1c8e059983ce7c7”}}}
Here’s the query to get the analysis – using the ID returned by the previous call. Replace the API key with your key.
curl “http://developer.echonest.com/api/v4/track/profile?api_key=TV2C30KYGHTUVIT9P&format=json&id=TRLFXWY14ACC02F24C&bucket=audio_summary”
Here is the response – which also contains a URL that you can use to get more detailed segment based acoustic analysis of the track.
{
“response”: { “status”: { “code”: 0, “message”: “Success”, “version”: “4.2” }, “track”: { “analyzer_version”: “3.2.2”, “artist”: “Tom Zicarelli”, “audio_md5”: “7edc05a505c4aa4b8ff87ba40b8d7624”, “audio_summary”: { “acousticness”: 0.64550727753299, “analysis_url”: “http://echonest-analysis.s3.amazonaws.com/TR/TRLFXWY14ACC02F24C/3/full.json?AWSAccessKeyId=AKIAJRDFEY23UEVW42BQ&Expires=1420763215&Signature=OLqYwvuzVmAqp1xLTi5x4CsYJuE%3D”, “danceability”: 0.5680872294350238, “duration”: 245.91673, “energy”: 0.19974462311717034, “instrumentalness”: 0.8089125726216321, “key”: 11, “liveness”: 0.10906007889455183, “loudness”: -25.331, “mode”: 1, “speechiness”: 0.03294587631927559, “tempo”: 93.689, “time_signature”: 4, “valence”: 0.43565861274829504 }, “bitrate”: 128, “id”: “TRLFXWY14ACC02F24C”, “md5”: “78ccac72a2b6c1aed1c8e059983ce7c7”, “samplerate”: 44100, “status”: “complete” } } }
Use the analysis_url returned by the previous request. Note that it expires a few minutes after the request. But you can always re-run the audio_profile request to get a new analysis_url
curl “http://echonest-analysis.s3.amazonaws.com/TR/TRLFXWY14ACC02F24C/3/full.json?AWSAccessKeyId=AKIASVIFEY23UEGE42BQ&Expires=1420763215&Signature=OLqYwvuzVmAqp1xLTi5x4CsYJuE%3D”
The analysis result is too large to display here. For more information, get the Echonest Analyze Documentation: http://developer.echonest.com/docs/v4/_static/AnalyzeDocumentation.pdf
Spectral slider plugin for Ableton Live
By Adam Rokhsar at Utami
http://makeyourselftransparent.tumblr.com
http://youtu.be/r-ZpwGgkGFI
The Sound Of Tubes, Tape & Transformers.
By Hugh Robjohns at Sound On Sound
http://www.soundonsound.com/sos/feb10/articles/analoguewarmth.htm

by soundwavescience
Using the python sms-tools library.
sms-tools: https://github.com/MTG/sms-tools
Here is a song made from the processed sounds:
mp3 version:
This project was an assignment for the Coursera “Audio Signal Processing for Music Applications” course. https://www.coursera.org/course/audio
Sounds were recorded from a shortwave radio between 5-10MHz.
freesound.org links to the sounds:
The sound is an AM shortwave broadcast station from between 7-8 MHz. It is speech with atmospheric noise and a digitally modulated carrier at 440Hz in the background.
I tried various approaches to removing the speech and isolating the carrier. But ended up using the following parameters to remove noise and speech, but for most part leaving a 440hz digital mode signal with large gaps in it.
After more experimentation, the following changes resulted in a cool continuous tone with speechlike quality (but not intelligible) and the background noise is gone.
Here is the full list of parameters:
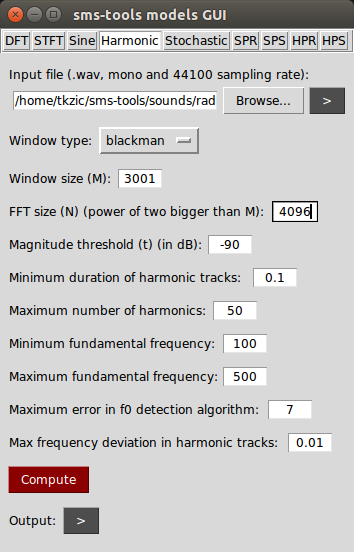
Here is a plot:
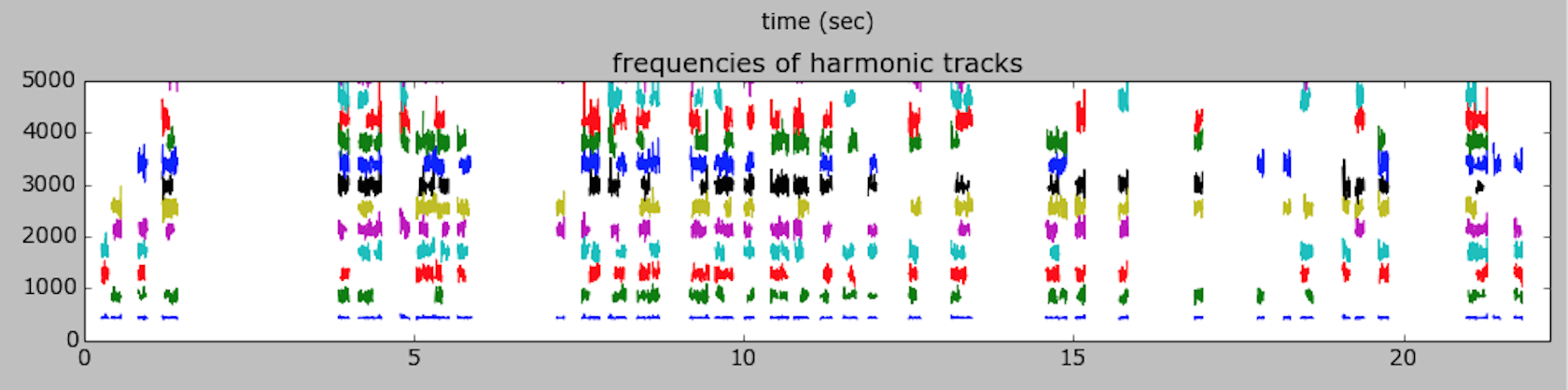
Here is the resulting sound of the sinusoidal part of the harmonic model:
The sound is continuous digital modulation (buzzing) from a shortwave radio between 7-8 MHz. The buzz is around 100Hz with atmospheric background noise.
Transformation using HPS (harmonic plus stochastic) model.
Not very impressive analysis, but the resynthesis had a very cool looking spectrogram due to some frequency shifting.
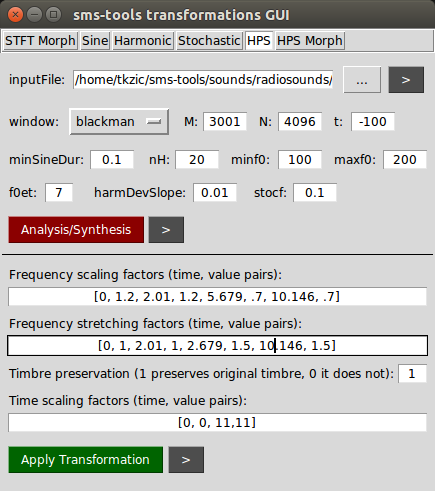
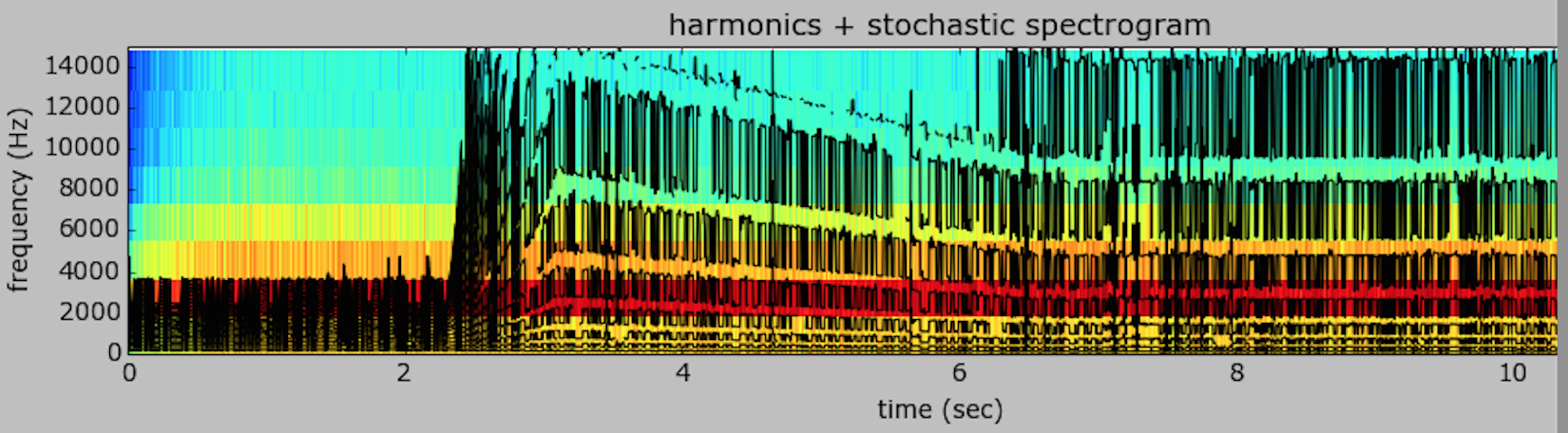
I realized that I had set f0min too high. Went back to using the HPR model without transformation to see if I could separate the tone. Here is the plot:
Here are the resulting sounds transformation (unused) and the sinusoidal/residual results that were used in the track.
A repeating pulse around from a shortwave radio between 7-8 MHz. The frequency of the pulse is around 1000Hz with a noise component.
Another noise filter – this was way more difficult due to high freq material.
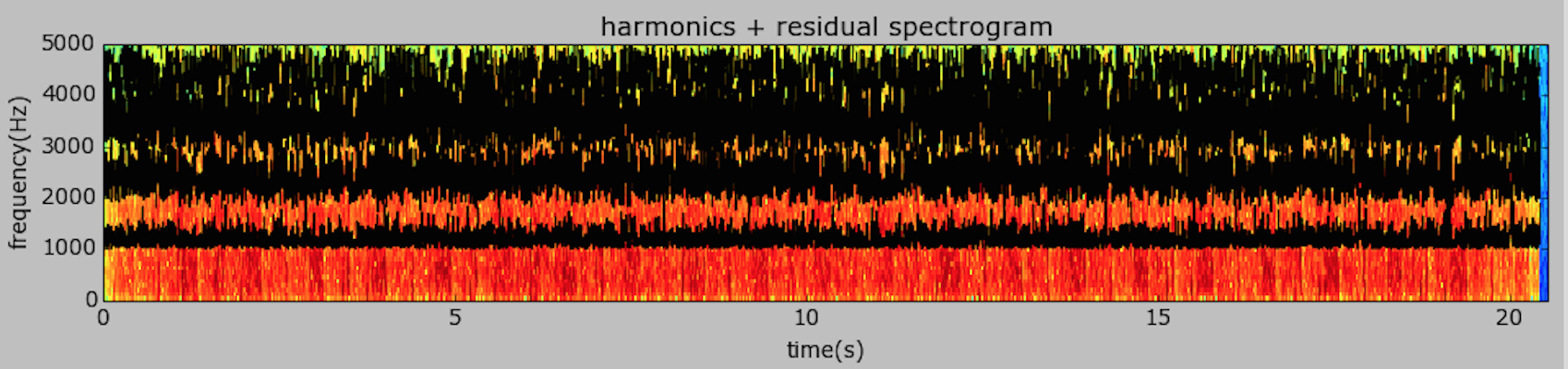
Instead, I went with a downward pitch transform, using the HPS model transform. Here are the resulting sounds from the HPR filter (unused) and the HPS transform.
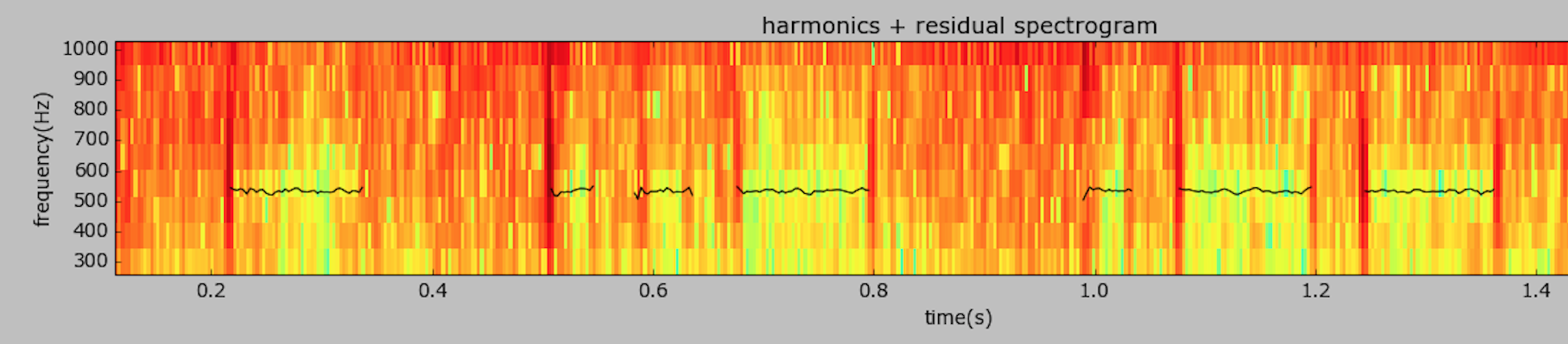
The sound contains typical amateur radio CW signals from the 40 Meter band, with several interfering signals (QRM) and atmospheric noise (QRN). Using the HPR model, I was able to completely isolate and re-synthesize the CW signal, removing all the noise and interfering signals.
Note that you can actually see the morse code letters “T, U, and W” on the spectrogram of model!
Here is the re-synthesized CW sound:
The WWV National Bureau of Standards “clock” station at 5MHz. A combination of pulses, tones, speech, and background noise.
I was trying to separate the voice from the rest of the tones and noise. After several hours and various approaches, I gave up. The signal may be too complex to separate using these models. There were some interesting plots with the HPR model
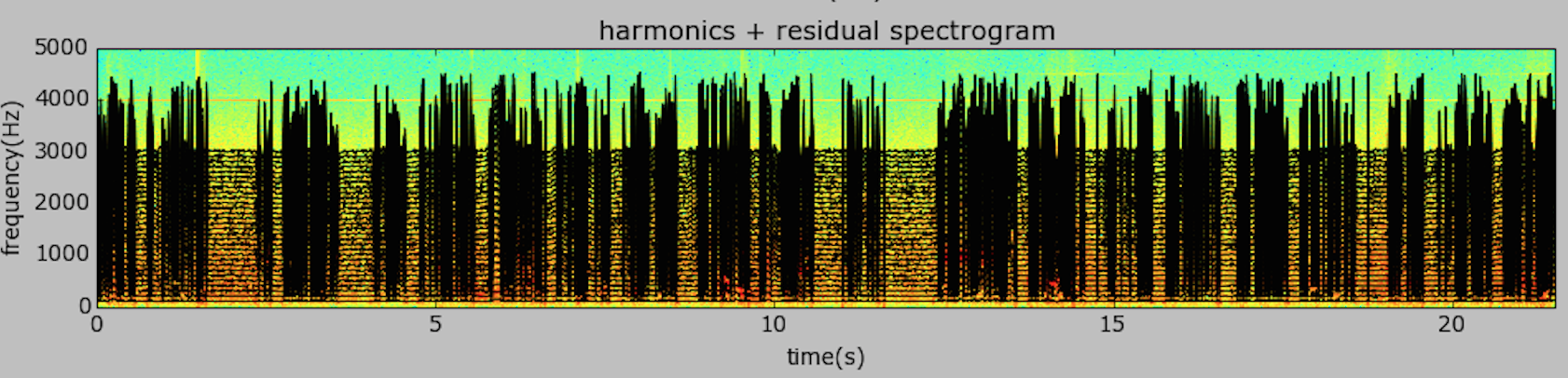
Finally decided to just isolate the 440 Hz. clock pulse from the rest of the signal:
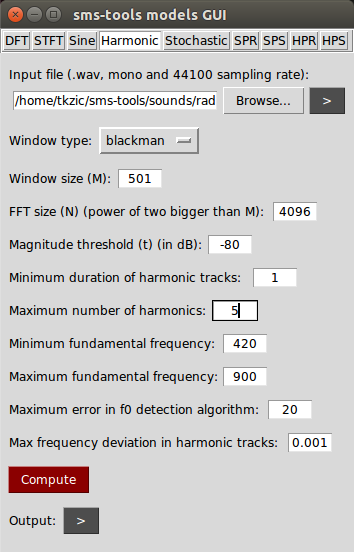

Here is the resulting sound (note that the tone starts several seconds into the sample)
John Coltrane: You can learn something from everybody, no matter how good or bad they play, everybody has something to say.
Sal Khan: In the future people will take agency for their own education.
For artists, everything is a tool.